Zero-downtime Docker Swarm Upgrade
APIHour #62 😎
Menu du jour
- Docker Swarm en 2 phrases
- Pourquoi mettre à jour notre cluster ?
- État des lieux d'entrée
- La valse des nodes
- Pour conclure
Docker Swarm en 2 phrases
- Outil de clustering de containers
- Bundlé nativement dans Docker
- Gère tout plein de trucs pour nous :
- Réseaux virtuels chiffrés inter-nodes
- Réplication (avec healthcheck, anti-affinité, etc)
- Secrets, configurations
- Pour résumer : un Kubernetes sans CSI, sans RBAC...
- ... Mais simple à maintenir, utiliser et stable.
=> APIHour #49 - RETEX sur Docker Swarm Mode (par notre Président)
Pourquoi mettre à jour ?
- Pour des raisons de sécurité (le cluster date de 2021) ;
- Pour ne pas repartir de zéro (et vautrer la prod) ;
- Pour prouver qu'on sait le faire (en cas de grosse panne) ;
- Pour avoir des (rares) nouvelles features de Docker et de Swarm ;
- Pour en profiter pour faire des grosses modifications sur le cluster ;
- Et pour "nettoyer" les instances (au fil des pannes, on a bidouillé parfois à la main...).
État des lieux d'entrée
- Un cluster de trois noeuds Swarm (Docker 20) ;
- Les instances sous Alpine 3.14 ;
- Exposées à travers un Load-Balancer (qu'on ne gère pas mais qu'on peut controler via DNS) ;
- Le tout sur OpenStack en IaC (OpenTofu) ;
- Et énormément de tooling en Ansible.
Le tout gère environ 50 (micro-)services en production. Quand ça tombe, on prend un ticket. Et on aime pas les tickets.
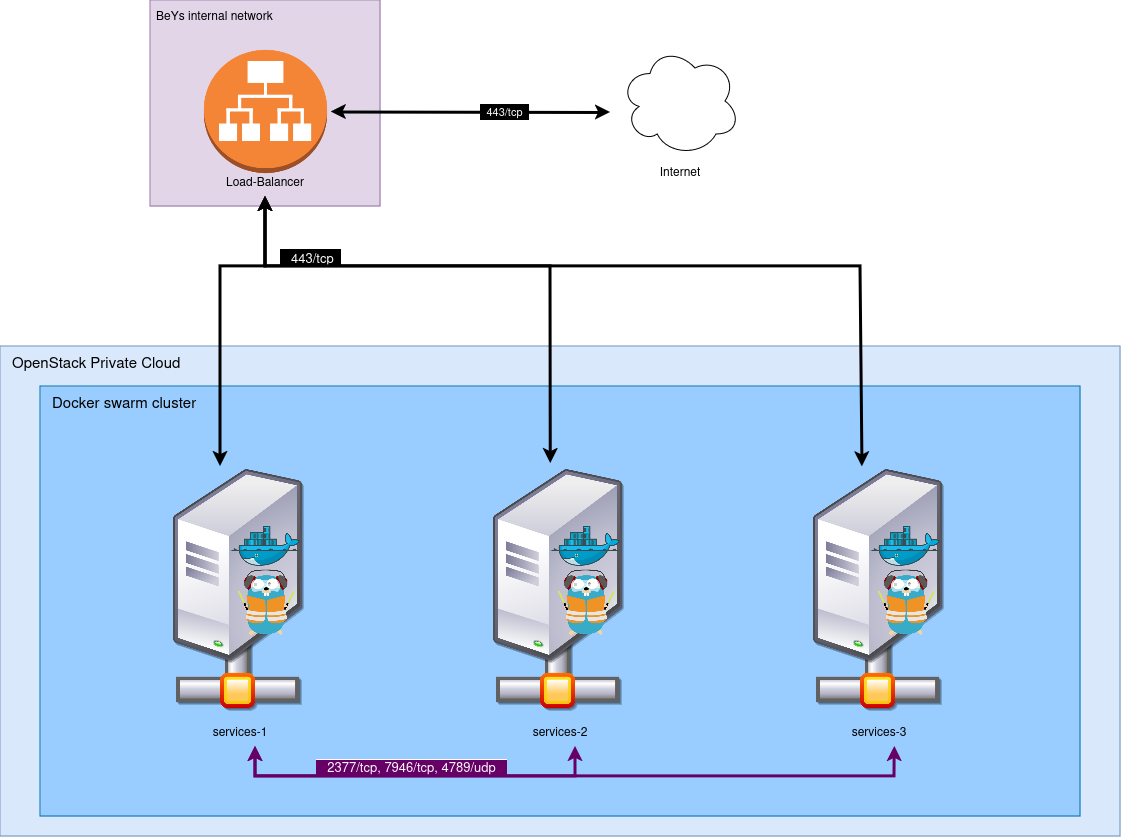
Objectifs :
- Passer sur Docker Engine 26.0.2 ;
- Et sous Alpine 3.18 ;
- Le tout proprement et sans downtime.
- Et comme on aime le challenge, on se fixe pour règle de ne jamais dépasser 3 instances actives.
La valse des nodes
Question : comment faire pour effectuer notre opération ?
- On retire notre première instance du record DNS (et donc du LB) ;
- On demande à Swarm d'évacuer les containers (
docker update --availability=drain swarm-1) ; - On retire le noeud du cluster (
docker node demote swarm-1 ; docker swarm leave) ; - On détruit et reconstruit l'instance ;
- On fait rejoindre le noeud au cluster ;
- On rajoute le cluster au DNS ;
- Et on recommence deux fois.
Les problèmes (forcément)
- On gère notre LB via DNS : vive le Time To Live 🙃
- On abaisse de 3600 à 300 secondes quand on s'en rend compte (temporairement)
- En attendant, on va prendre un café...
- Et à chaque entrée/sortie de node, il a fallu attendre 5-6 minutes.
OpenTofu, relation amour-haine
- Quand nous avons fait notre code OpenTofu, nous n'avions pas anticipé de détruire des machines spécifiques
- Nous utilisions un
countpour créer nos instances. Pour scale-up/down, c'est super, pour le reste, non. - => De gros changements pour passer sur des
for_eachavec des listes - Et aller bidouiller le
.tfstateen dur pour ne pas devoir tout détruire et reconstruire. 😎
Hormis ça, tout va bien !
- Notre outillage Ansible se comporte à merveille ;
- Swarm retrouve tout seul ses petits quand on rajoute les noeuds ;
- Les sorties de noeuds se font proprement et sans interruptions => 0 tickets reçus 🎉
- Et nous sommes sur un cluster tout neuf et à jour !
Pour conclure
- Docker Swarm c'est cool ;
- Ansible c'est bien aussi ;
- OpenTofu c'est bien mais
count= ☠️ - On s'en sort avec des outils encore meilleurs et une meilleure confiance dans notre infra !
- ... Et on est déjà plus à jour donc faut tout refaire (mais ce coup-ci, on est prêts).