Bidouilles et benchmarks de SeaweedFS
This article is also available in English.
Au cours de cette année, j’ai été confronté chez un client à l’épineux sujet du stockage objet en entreprise : Au sein de cette entreprise, il est impossible d’envisager une solution “cloud” pour leur stockage : en effet, ils ont de très nombreuses contraintes réglementaires et légales qui leur empêche formellement de déléguer le stockage des données à un prestataire externe. La question se pose donc : comment leur fournir un stockage objet efficace, scalable, on-premise, et de préférence sans payer des frais de licences absurdes.
Si notre regard s’était initialement porté sur MinIO, c’était sans compter sur la gestion absolument catastrophique de l’entreprise éponyme de sa version communautaire : fin de distribution des builds, retrait de plusieurs fonctionnalités importantes… Et c’est ainsi que mon regard c’est porté sur SeaweedFS, un projet que je suis de loin depuis (très) longtemps, mais que je n’avais jamais eu le temps d’expérimenter dans des conditions extrêmes.
Aujourd’hui donc, nous testons SeaweedFS pour stocker des données en réplication actif-actif sur plusieurs datacenters, en temps-réel. Rien que ça.
SeaweedFS, sa vie, son oeuvre
Créé en 2014, SeaweedFS est un système de fichiers distribué open-source, designé pour stocker et accéder efficacement à des milliards de fichiers. Sa
force principale réside dans son temps d’accès aux fichiers en O(1) ; autrement dit : peu importe la taille de votre cluster, le temps d’accès au
fichier sera la même. Construit pour fonctionner en mono-node, en multi-node, en mono-datacenter, en multi-datacenter, Seaweed se positionne comme un
couteau suisse du stockage, prêt à répondre à n’importe quel besoin. Par ailleurs, certaines features de Seaweed sont assez rares pour les souligner,
notamment la présence d’erasure coding et un FUSE POSIX-Compliant (tl;dr : vous pouvez monter votre object storage comme une clé USB sur votre
PC ou serveur).
Bien entendu, Seaweed est fourni avec toute une palanquée de connecteurs : S3, CSI Kubernetes, etc. Bref, sur le papier, c’est le produit parfait pour du stockage ; raison de plus pour me donner envie de l’essayer !
Quelques éléments de langage avant qu’on poursuive ensemble :
- Seaweed FS fonctionne avec des noeuds master chargés de maintenir une cohérence et une connaissance du cluster ;
- Puis, Seaweed FS a besoin de noeuds de volume, qui stockent les données.
- Enfin, Seaweed FS dispose de filer, un serveur additionnel qui permet d’exposer les volumes au travers des multiples interfaces “classiques” pour du stockage : FUSE, WebDAV, S3, etc.
SeaweedFS propose de la réplication en temps-réel sur le cluster. Pour cela, nous utilisons un code à trois chiffres permettant de définir la
réplication, XYZ, où :
Xindique le nombre de fois que la donnée doit être répliquée dans d’autres datacenter ;Yindique le nombre de fois que la donnée doit être répliquée dans le même datacenter mais dans un rack différent ;Zindique le nombre de fois que la donnée doit être répliquée dans le même rack.
Ainsi, une réplication à 200 indique que la donnée doit être répliquée dans 2 autres datacenters que celui d’origine (on stocke donc 3 fois la
donnée). Une réplication à 101 indique qu’on va stocker la donnée dans un second datacenter, et une seconde fois dans le rack d’origine.
Lors de l’inscription d’un noeud de volume, on renseignera donc son datacenter et son rack. Attention, SeaweedFS est consistency-first : L’écriture de la donnée n’est confirmée que lorsque l’ensemble des répliques demandées ont pu être écrites !
Les expérimentations du jour ne se focalisent pas sur les considérations de sécurité : Seaweed propose plusieurs options pour contrôler l’accès à la donnée, nous n’explorons donc pas cette partie-là puisque la solution est disponible “out of the box”.
Tests effectués (multi-DC sans réseau interne)
Objectifs de la mission
L’objectif de ce test est de vérifier le comportement d’un cluster SeaweedFS en réplication active-active multi-master sur la partie stockage S3 et FUSE (Seaweed Filer) : performances, taux d’erreur, réplication, scalabilité, résilience, sauvegarde et restauration.
Les éléments observés seront :
- La disponibilité de Seaweed : le cluster est-il capable de répondre à nos demandes ?
- La disponibilité de la donnée : Suis-je en mesure d’accéder à 100% de ma donnée ?
- Performance : Quelles sont les débits en écriture, en lecture aléatoire, autant en mode S3 qu’en FUSE ?
Installation
Pour cette expérimentation grandeur nature, nous allons provisionner 7 VMs auprès de plusieurs providers différents :
- Noeuds de volume :
- 2x EM-A116X-SSD (Scaleway - Dedibox Elastic Metal - Aluminium Range) (0.077€/h)
- 2x CAX21 (Hetzner - Cloud - Shared Cost-Optimized) + 400Go block storage (coût total : 0.09€/h)
- Noeuds master + filer :
- 2x CX23 (Hetzner - Cloud - Shared Cost-Optimized) (0.0067€/h)
- 1x DEV1-M (Scaleway - Cloud - Development Instances) (0.0198€/h)
Considérations importantes :
- Seaweed sera installé à même les machines. L’OS cible est Debian 13 (trixie).
- Pour des raisons de coût, le déploiement sera totalement automatisé (les playbooks Ansible et les OpenTofu sont disponibles sur Github)
- Une fois de plus, la sécurité n’est pas la priorité de notre expérimentation : nous serons donc en “open bar” (tout flux ouverts).
- Pour nous simplifier la tâche, nous créerons des enregistrements DNS (le domaine est chez OVH) :
master-X.lab.forestier.repour les noeuds maître ;volume-X.lab.forestier.repour les noeuds volume ;masters.lab.forestier.re(DNS round-robin sur les noeuds maître) ;volumes.lab.forestier.re(DNS round-robin sur les noeuds volume).
L’ensemble des données permettant de déployer notre infra test est disponible sur GitHub.
⚠️ Considérations importantes
Il est impératif de noter que les conditions de déploiement de la solution sont extrêmement mauvaises : Nous sommes sur 2 providers sans fibre noire / dédiée à disposition, donc nous transitons par le réseau Internet public (avec la latence et les rebonds induits) ; sur du matériel hétérogène et qui n’est pas destiné à effectuer du stockage “production-grade”. Les performances obtenues sont donc à relativiser, tenant compte de ces spécificités techniques. Dans un monde optimal, nous serions dans 2 datacenters sur du matériel équivalent, avec une fibre dédiée permettant de transiter directement et à haute vitesse.
Détails et performances de l’infra de base
Pour le test ci-dessous, nous sommes donc sur 2 datacenters différents, sans réseau dédié à la communication entre ces deux datacenters. Voici le traceroute DC2 (Hetzner) -> DC1 (Scaleway). La latence moyenne au ping est de 40ms, et le taux de transfert moyen est de 48Mbps (obtenu en téléchargeant un fichier de 1Go).
traceroute to 2001:bc8:711:756:dc00:ff:fed1:3f71 (2001:bc8:711:756:dc00:ff:fed1:3f71), 30 hops max, 80 byte packets
1 fe80::1%eth0 (fe80::1%eth0) 2.936 ms 3.123 ms 3.217 ms
2 31801.your-cloud.host (2a01:4f9:0:c001::2827) 0.426 ms 0.446 ms 0.470 ms
3 * * *
4 spine3.cloud1.hel1.hetzner.com (2a01:4f9:0:c001::a0e9) 1.370 ms spine4.cloud1.hel1.hetzner.com (2a01:4f9:0:c001::a0ed) 1.522 ms 1.783 ms
5 * * *
6 core32.hel1.hetzner.com (2a01:4f8:0:3::6bd) 1.136 ms core31.hel1.hetzner.com (2a01:4f8:0:3::6b9) 0.758 ms core32.hel1.hetzner.com (2a01:4f8:0:3::6bd) 0.708 ms
7 * * *
8 * * *
9 core2.ams.hetzner.com (2a01:4f8:0:3::201) 27.276 ms core2.ams.hetzner.com (2a01:4f8:0:3::205) 27.136 ms core2.ams.hetzner.com (2a01:4f8:0:3::201) 27.192 ms
10 2a01:4f8:0:e0f0::11e (2a01:4f8:0:e0f0::11e) 28.698 ms 27.542 ms 27.525 ms
11 2001:bc8:1400:2::3e (2001:bc8:1400:2::3e) 28.857 ms 2001:bc8:1400:2::18 (2001:bc8:1400:2::18) 28.909 ms 2001:bc8:1400:2::42 (2001:bc8:1400:2::42) 28.841 ms
12 2001:bc8:0:1::18f (2001:bc8:0:1::18f) 37.518 ms 2001:bc8:0:1::18b (2001:bc8:0:1::18b) 37.905 ms 2001:bc8:0:1::18f (2001:bc8:0:1::18f) 37.231 ms
13 2001:bc8:400::36 (2001:bc8:400::36) 38.773 ms 38.391 ms 38.242 ms
14 2001:bc8:400:1::1b1 (2001:bc8:400:1::1b1) 38.988 ms 38.634 ms 2001:bc8:400:1::1bb (2001:bc8:400:1::1bb) 38.377 ms
15 2001:bc8:410:1018::1 (2001:bc8:410:1018::1) 41.636 ms 41.872 ms 40.920 ms
16 2001:bc8:410:1018::c (2001:bc8:410:1018::c) 36.908 ms 37.206 ms 37.860 ms
17 3f71-fed1-ff-dc00-756-711-bc8-2001.instances.scw.cloud (2001:bc8:711:756:dc00:ff:fed1:3f71) 36.878 ms 36.993 ms 37.837 ms
Le cluster est configuré afin que l’ensemble des volumes et buckets soient en duplication 100 : Une fois dans un autre datacenter. L’ensemble des
fichiers sont donc commités par Seaweed entre DC1 et DC2.
Les performances des disques sont (obtenu via dd d’un fichier de 10Go) :
- Sur les noeuds de stockage de DC1 : Write 2.6GBps / Read 4.9GBps
- Sur les noeuds de stockage de DC2 : Write 304MBps / Read 323MBps
Smoke test - Vérifier que le cluster est UP
Après avoir lancé le script d’installation, nous accédons aux trois panneaux d’administration (port 23646/tcp). L’interface graphique est en
alpha, donc des petits bugs sont visibles ; notamment sur la partie “Master nodes”, qui n’indique que le noeud actuellement élu par Raft (les
autres sont masqués). Cependant, les logs du cluster indiquent bien que le cluster est en HA avec un quorum actif.
Les volumes eux sont bien tous visibles, et correctement labellisés. Nous sommes prêts à commencer !
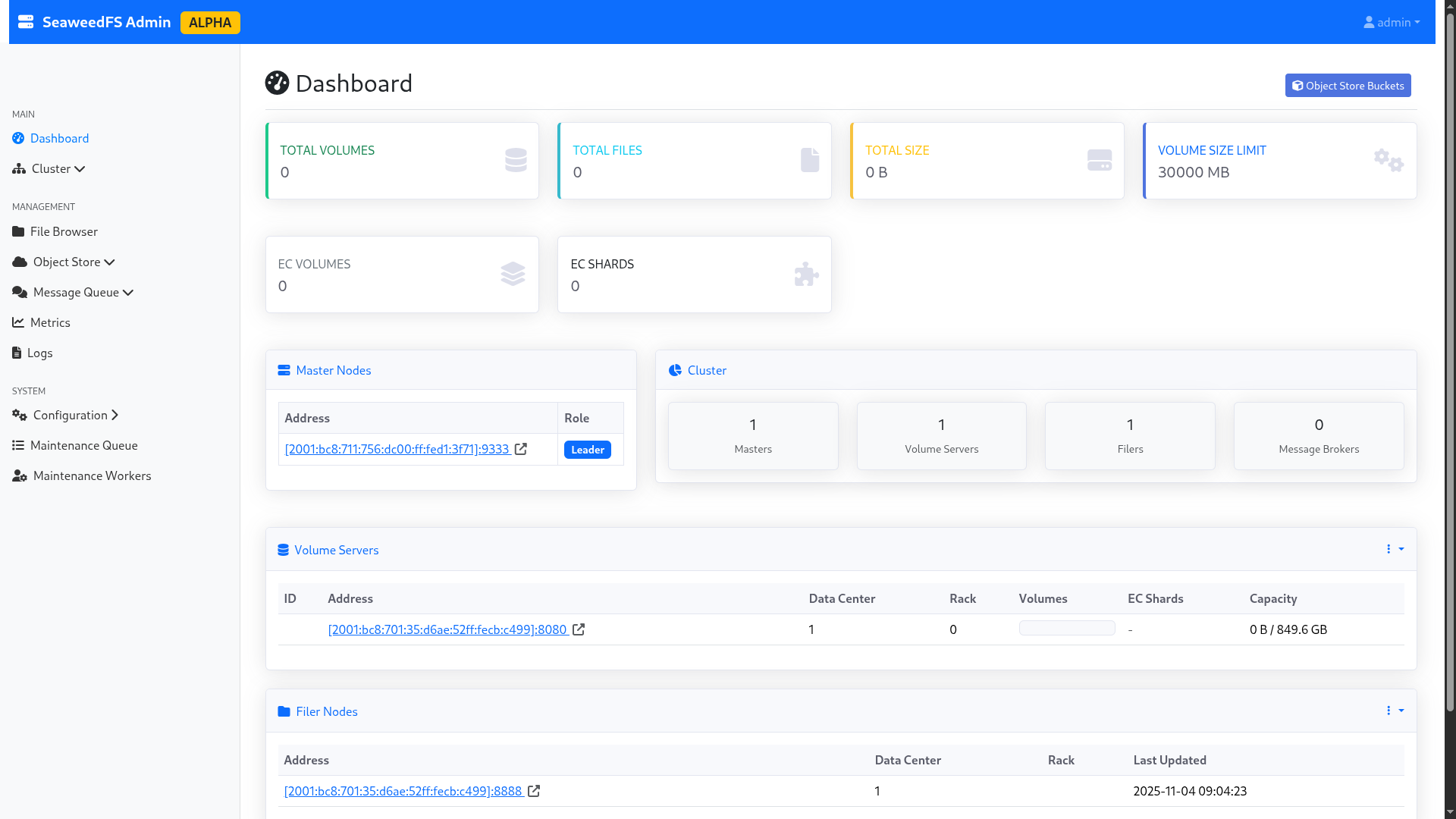
Figure 1 : L’interface admin de SeaweedFS.
Perte d’un nœud master (aucune charge)
Tout d’abord, il faut savoir que SeaweedFS se base sur l’algorithme de consensus Raft, très utilisé dans le monde des systèmes hautement disponibles :
Docker Swarm, Kubernetes, MariaDB et bien d’autres utilisent ce protocole de consensus. De manière globale, on considère que pour survivre à la perte
de n nœuds, il vous faut 2n+1 nœud au sein de votre cluster. Par exemple, un cluster composé de 3 masters pourra continuer à fonctionner avec 1
nœud manquant, un cluster de 5 avec 2 nœuds, etc… Dans Raft, les contrôleurs élisent un “responsable”, qui s’occupe de gérer le cluster de manière
active ; alors que les autres se contentent de maintenir le quorum. Lorsque ce nœud est perdu, une nouvelle élection a lieu pour définir un nouveau
responsable.
Lors de la perte d’un nœud master, le cluster arrive à se retrouver et revenir en ligne. Deux cas de figure :
- Si le nœud perdu n’est pas le nœud principal : Les nœuds restants (dont le responsable) constatent la perte du nœud et continuent à fonctionner sans lui. L’opération est transparente.
- Si le nœud perdu est le nœud principal : Les nœuds restants lancent une élection pour obtenir un nouveau responsable. Dans les cas testés, le cluster met quelques secondes (4-5 secondes) à trouver un consensus, pendant lequel le cluster n’est plus administrable. Toutefois, les volumes déjà créés continuent de fonctionner.
Note : SeaweedFS ne recommande pas forcément d’avoir plusieurs masters : cela ne répond d’après eux qu’à des cas de figures rares et introduit une charge supplémentaire à la gestion du cluster. Les auteurs prennent en exemple Google, qui tourne en mono-master sur sa solution de stockage maison depuis des années. Bien que je souscrive à l’idée que la mise en haute-disponibilité du management répond à un besoin assez peu fréquent, je peux attester (pour l’avoir vécu, et expérimenté) que ce genre de systèmes m’ont déjà sauvé la mise à plusieurs reprises.
Performances en mode Object HTTP (S3) en configuration nominale
Pour cet exemple, je vais construire deux buckets depuis l’interface graphique de Seaweed, sans quota, et envoyer dans chaque bucket plusieurs Go de
données aléatoires. Le premier bucket sera rempli par un serveur tiers chez OVH déjà en ma possession, l’autre avec mon PC personnel. J’utilise l'
outil rclone pour me connecter aux buckets.
Plus en détail, je vais simuler l’envoi de l’ensemble du code source de OpenBAO (https://github.com/openbao/openbao) depuis mon PC : environ 350Mo, répartis sur plus de 5000 fichiers. Le tout sur une connexion 4G instable.
Sur mon serveur, je simulerai l’envoi de 2Go de données aléatoires décomposées en fichiers de 1Mo. Le serveur dispose d’une fibre optique 1Gbps unmetered. Deux cas d’usage radicalement différents donc.
Mon rclone dispose de la configuration par défaut du provider S3 : 4 envois en parallèle maximum ; aucune optimisation sur la préservation de la connexion TCP ou autre. Pour ne rien arranger, je vais passer par le DNS round-robin, qui va donc faire changer d’hôte mon rclone à chaque envoi de fichier. Dans un monde réel, on aurait un équipement réseau type F5/HAProxy qui nous ferait une belle VIP avec anti-affinité.
La configuration du rclone est la suivante :
- Type : S3
- Provider : SeaweedFS
- AccessKey / SecretKey : Celles générées pour mon user dans la GUI
- Endpoint : http://volumes.lab.forestier.re:8333/
- ACL : Private
Le test démarre à 10:44:00. Très vite, l’interface graphique de SeaweedFS commence à montrer les fichiers en train de se peupler. Durant tout le temps du test, l’interface graphique reste accessible, et je peux instantanément re-télécharger un fichier déjà envoyé depuis l’UI. L’attente est imperceptible de ce côté là.
Je coupe le test à 10:54:00. Les deux rclone ont eu le temps d’envoyer :
- Pour celui en 4G instable : 2.1Mo dans 456 objets (Soit 3.5ko/s)
- Pour celui en fibre : 408Mo dans 408 fichiers (Soit 680ko/s)
Les performances sont… Abominables ; probablement à cause de mon DNS round-robin. Je change donc légèrement la configuration de mon rclone : Je passe un rclone sur http://volume-1.lab.forestier.re:8333/, l’autre sur http://volume-3.lab.forestier.re:8333/ (j’ai sélectionné ces noeuds au hasard).
Je lance à 10:57:10, et coupe à 11:07:10. Pour comparer, j’ai créé deux buckets supplémentaires qui m’ont servi à lancer cette version de la configuration. Les résultats sont les suivants :
- Pour celui en 4G instable : 2.2Mo dans 368 objets (Soit 3.6ko/s) ;
- Pour celui en fibre : 376Mo dans 376 objets (soit 626ko/s).
Contrairement à mon intuition, le fait de forcer un filer spécifique atténue les performances. Je modifie une fois de plus mon rclone pour augmenter le nombre de fichiers a envoyer en parallèle (et remettre mon DNS round-robin), puisque mon set de données s’y prête : de nombreux petits fichiers. Je passe la valeur à 20 ; et je relance à 11:10:30. A 11:20:30, les résultats sont les suivants :
- Pour celui en 4G instable : 2.2Mo dans 368 objets (Soit 3.6ko/s) ;
- Pour celui en fibre : 376Mo dans 376 objets (soit 626ko/s).
Visiblement, un plafond de verre de performance s’applique à notre infrastructure ; probablement à cause de la communication inter-datacenter. Suite à ces résultats plus que douteux, je décide de modifier mon schéma de test (on va en reparler dans quelques secondes).
Malgré des performances décevantes, il est tout de même à noter que :
- Les fichiers sont tous bien répliqués sur disque entre les deux datacenters, comme demandé ;
- L’interface graphique et les APIs exposées par Seaweed ont parfaitement tenu face à la demande ;
- L’interconnexion avec rclone est validée.
Tests effectués (multi-DC avec réseau interne)
Afin de continuer mes tests dans de meilleurs conditions, je décide de changer mon braquet de position, et d’abandonner l’idée de fonctionner sur deux providers différents : Je vais déployer l’intégralité de mon infra test chez Scaleway, sur 2 datacenters leur appartenant, avec un réseau privé virtuel (VPC) pour connecter mes services entre les deux DC.
Cette approche va me permettre d’expérimenter mon système de stockage dans des conditions un peu plus proches de la réalité : un seul réseau interne, des rebonds réduits, une connectivité améliorée.
Voici donc le nouveau lab :
- Noeuds de volume :
- 4x EM-A116X-SSD (Scaleway - Dedibox Elastic Metal - Aluminium Range) (0.077€/h)
- Noeuds master + filer :
- 3x DEV1-M (Scaleway - Cloud - Development Instances) (0.0198€/h)
Le tout sur un VPC. Les noeuds communiqueront donc entre eux via l’IP interne au VPC, et ne feront plus la grande boucle internet.
Il est à noter que j’ai fait en sorte à préserver les proportions précédentes, pour éviter de fausser le test. Enfin, à titre d’information, j’ai conservé Scaleway tout simplement car les performances sur disque étaient plus élevées que sur les serveurs de Hetzner. C’est assez logique, puisque les machines que j’utilise chez Scaleway sont des dédiés facturés à l’heure, alors que chez Hetzner, ce sont des instances avec un point de montage réseau (ce qui dégrade inéluctablement la performance). C’est donc un choix purement technique lié à la finalité du projet ; les solutions d’Hetzner étant, au quotidien, aussi agréables à utiliser que celles de Scaleway (et c’est un très joli compliment, Scaleway étant mon cloud provider préféré !).
Les serveurs seront déployés sur les zones WAW-2 et WAW-3 de Scaleway.
A titre d’information, voici les performances obtenues avec ce setup :
- Ping WAW-2 => WAW-3 : 1.96ms (et via lien public : 2.22ms)
- Transfert WAW-2 => WAW-3 : 267Mbps (et via lien public : 34Mbps)
- Écriture sur disque : tout pareil qu’avant.
Nous sommes repartis pour un tour ! Et pour faire les choses dans les règles de l’art, on recommence… Avec le même mode opératoire.
Comme pour tout à l’heure, les scripts d’installation sont disponibles sur GitHub.
Performances en mode Object HTTP (S3) en configuration nominale
Nous reprenons le même mode opératoire que le test précédent (OpenBAO, rclone, etc). Les résultats obtenus en 10min00s d’upload sont :
- Pour celui en 4G instable : 2.2Mo dans 392 objets (Soit 3.75ko/s) ;
- Pour celui en fibre : 408Mo dans 408 objets (soit 696ko/s).
Visiblement, les performances plafonnent même avec une infra beaucoup plus rapide entre les noeuds. Deux idées de tests me viennent alors :
- Tenter avec des gros fichiers (de 50Mo), pour vérifier l’impact de l’ouverture/fermeture répétée des flux TCP ;
- Tenter avec des volumes sans réplication.
Avec des plus gros fichiers
Pour des raisons pratiques, je ne lance que depuis mon PC fibré, avec des fichiers de 50Mo au lieu de 1Mo. Au bout de seulement 6min54s, les 5Go de fichiers (100 chunks de 50Mo) sont en ligne… Soit 12.36Mo/s, un résultat bien plus honorable.
Note importante : j’ai conservé en fond l’upload du code source d’OpenBAO depuis ma 4G instable, pour conserver une utilisation du cluster similaire.
Le protocole S3 semble donc bien mieux supporter les gros fichiers (ce qui est peu étonnant : les gros fichiers demandent moins d’ouverture/fermeture de connexion TCP, donc moins de temps perdu à attendre une reconnexion au serveur).
Par acquis de conscience, je décide de garder mon test sans réplication, mais je décide d’ajouter, par curiosité, le test “sans réplication ET avec des gros fichiers”.
Chose intéressant, le bucket apparaît avec une taille de 10.1Go dans l’interface (car les réplicas sont comptées dans la taille réelle du bucket).
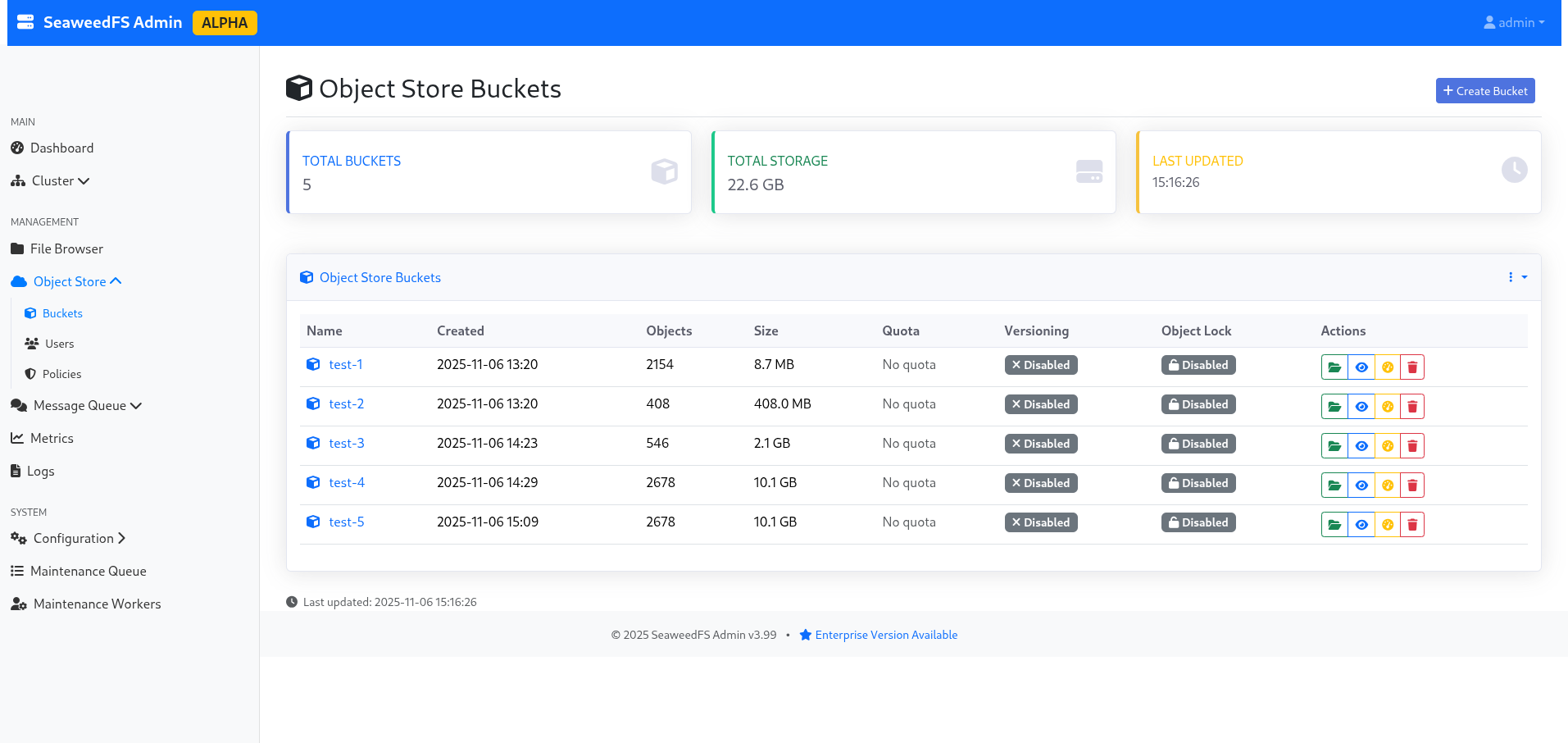
Figure 2 : La liste des buckets, indiquant 10.1Go à cause de la réplication.
Je profite du temps de reconfiguration pour explorer un peu l’interface d’admin, et notamment la partie “volumes”, qui me permet de voir le split effectif de mes données, leur réplication, leur statut, quel noeud est actif et lequel est en réplication… Bref, c’est sacrément mignon comme technologie, et même pour un noob du stockage comme moi, c’est compréhensible !
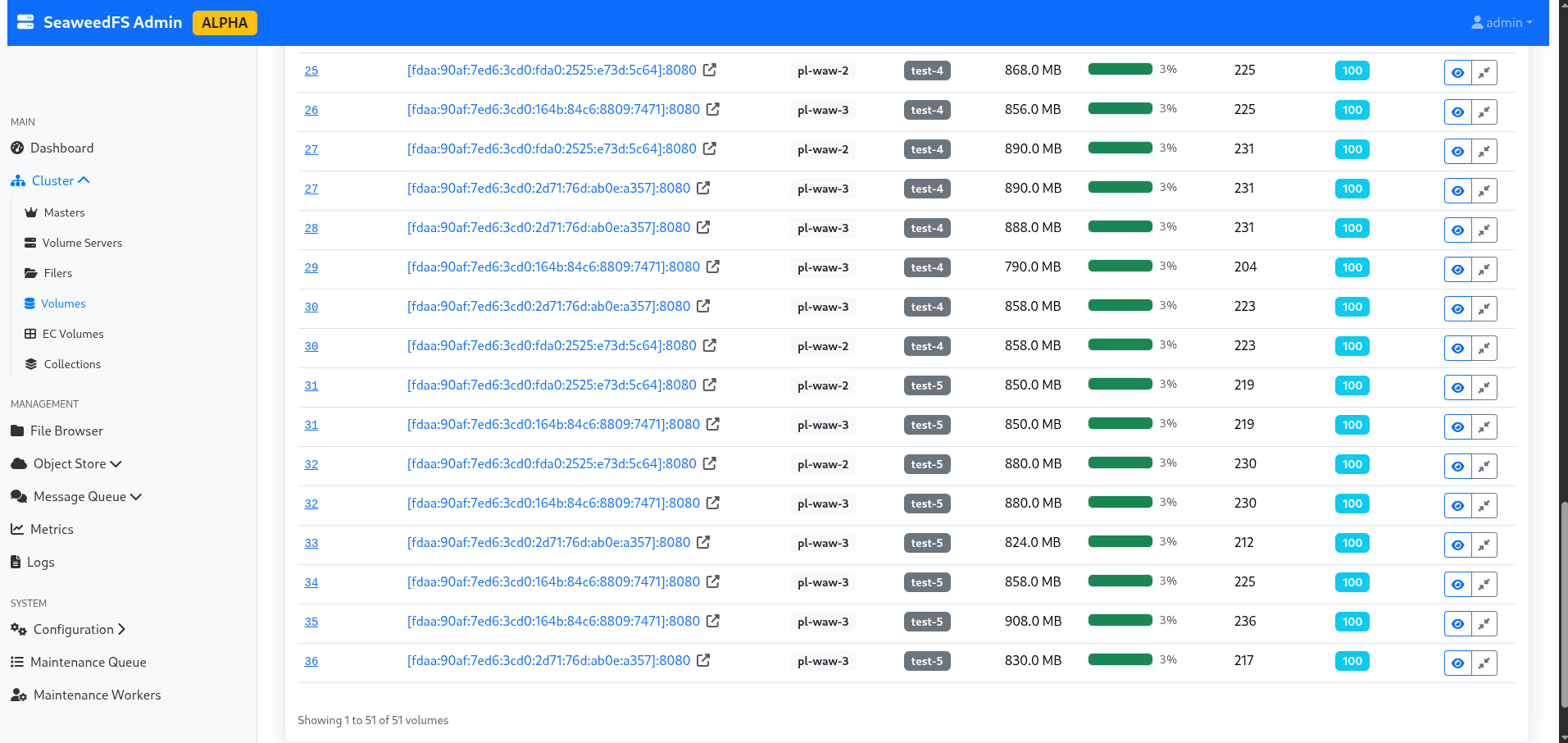
Figure 3 : Liste des volumes par bucket.
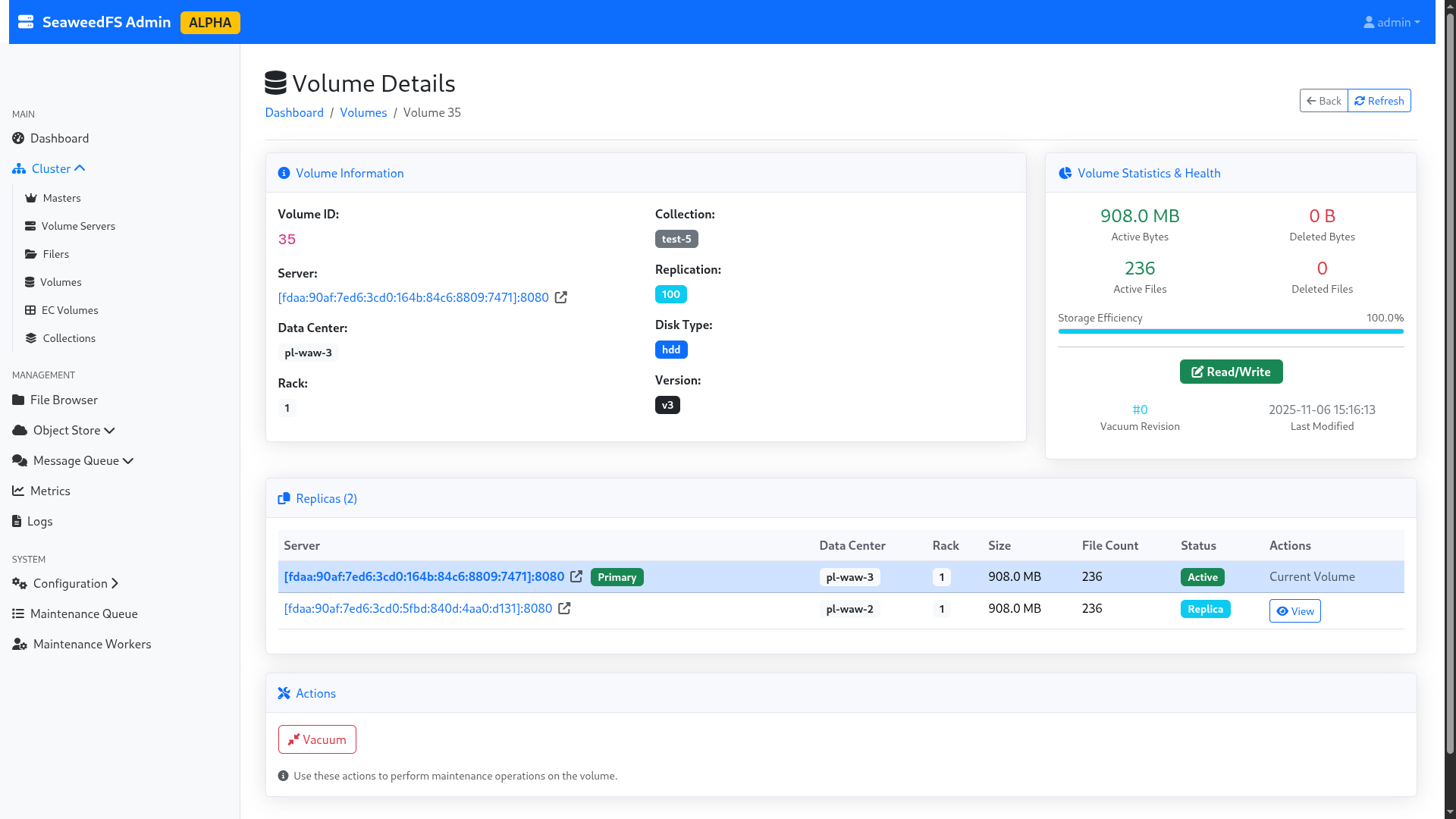
Figure 4 : Détails d’un volume.
Sans réplication et avec des gros fichiers
Je relance mon envoi de 5Go de fichiers de 50Mo, avec toujours en toile de fond mon envoi de code source OpenBAO (le fil rouge de ce billet de blog, au final !).
La réplication met au total 6min16s sans réplication, soit un débit de 13.61Mo/s. Du léger mieux, mais pas de quoi sauter au plafond. Cependant, chose intéressante, cela signifie que la réplication semble se faire à un coût très faible en terme de perte de performance.
Pour le fun, je m’amuse un peu : je tente d’envoyer un seul gros fichier de 1Go sans réplication, puis avec réplication. Le temps que cela a mis :
- Sans réplication : 35 secondes (soit 29,25Mo/s)
- Avec réplication : 35 secondes (soit 29,25Mo/s)
=> La réplication n’a donc pas d’impact significatif sur les performances en mono-écriture (et sur du multi-écriture, négligeable comme nous avons pu le voir auparavant).
Il est d’ailleurs à noter que 29,25Mo/s donne ~234Mbps. Hors, le lien WAW-2 => WAW-3 est annoncé à 267Mbps. Il est donc fortement probable que le réseau fasse une fois de plus office de bottleneck dans notre test. N’ayant aucune autre infrastructure capable de mieux faire, je me contenterai de ce résultat. Toutefois, si quelqu’un dispose d’un backbone dédié entre deux datacenters géographiquement éloignés avec du 1Gbps et des disques type NVMe, je suis preneur des retours !
Performances en mode Object HTTP avec simulations de panne (master/storage/datacenter)
Pour cette petite expérience, je vais envoyer à nouveau 5Go de fichiers aléatoires de 50Mo chacun, et, au cours du transfert, je vais effectuer un
kill -9 sur un nœud de volume aléatoire. Le but est de voir le comportement du cluster, et de regarder l’impact sur les performances. Je serai en
réplication 100 (soit réplication à travers les 2 datacenters en temps réel). Puis, je ferai la même expérience avec un kill -9 sur un noeud
master aléatoire. Enfin, je ferai cette action sur tout un datacenter !
C’est donc parti pour la première étape.
Perte d’un nœud de stockage
Je débute mon expérience à 16h51m00s, et je coupe le serveur volume-pl-waw-2-0 à 16h51m11s, soit en plein transfert rclone. Par “coupure”, j’entend
par là que je coupe non seulement le nœud de volume, mais également le nœud filer, pour simuler un réel downtime du nœud. L’opération d’écriture se
termine à 16h57m23s, soit 6min12s (13,76Mo/s). Pour rappel, sans perte de nœud, nous étions à 6min54s (12.36Mo/s).
Même si le débit est plus élevé avec un nœud en moins, l’amélioration est à relativiser : Nous sommes à moins de 10% d’écart, avec de nombreux facteurs entrant en jeu, notamment la qualité et la disponibilité du réseau entre le serveur d’upload et le cluster. L’écart est donc non significatif.
Je profite de l’occasion pour vérifier la disponibilité de la donnée dans le cas actuel, en téléchargeant l’intégralité du bucket test-5, qui était
en réplication active et qui utilisait fortement le serveur supprimé. Je parviens sans problème à télécharger l’ensemble des données, le cluster ayant
détecté la perte du nœud.
⚠️ Limitation importante : SeaweedFS ne dispose pas d’auto-heal en version communautaire; le cluster ne rebalance donc pas les données automatiquement vers d’autres nœuds pour combler le vide. A titre purement personnel, pour avoir vécu des auto-rebalance avec CephFS, je considère quasiment cela comme un avantage… Mais chacun son avis. 😉
Je relance le volume et le filer sur le serveur déconnecté, pour revenir en configuration nominale. Le nœud remonte automatiquement dans le pool, et Seaweed se remet à l’utiliser, comme si rien n’était arrivé.
Perte d’un nœud master
C’est reparti pour un tour, et cette fois-ci, ma victime sera lab-master-1. Je lance la copie à 17h07m10s, et je coupe le nœud à 17h07m39s. Le
rclone continue à s’exécuter sans erreur. L’interface graphique continue à s’exposer. La copie termine en 6min34s… Soit aucun impact visible.
Je rallume le nœud, et poursuit mes tests.
Perte d’un datacenter
Pour rappel, notre infra est déployée à travers deux régions : “WAW-2” et “WAW-3”. Le but du jeu ici est de couper intégralement “WAW-2”, de la
manière la plus sale possible (kill -9 de tout ce qui contient weed dans le nom), pour simuler une panne subite et inattendu d’un datacenter
entier.
Je démarre la copie à 17h29m30s, et je coupe simultanément toute la région “WAW-2” (1 master, 2 volumes) à 17h29m45s. Le rclone commence rapidement à afficher des erreurs 500, car l’écriture ne peut plus s’effectuer car l’ensemble du datacenter “WAW-2” est hors-ligne ; et SeaweedFS attend que toutes les écritures demandées soient validées pour confirmer l’écriture d’un fichier. Je relance donc le datacenter “WAW-2” pour revenir à un cas nominal.
status code: 500, request id: 1762447203809093757, host id:
2025/11/06 16:40:05 ERROR : chunk_0012.bin: Failed to copy: InternalError: We encountered an internal error, please try again.
Le message d’erreur côté utilisateur.
En quelques secondes, le cluster revient à lui, et le transfert reprend. Il est à noter que durant la perte du datacenter “WAW-2”, les données restaient parfaitement accessibles en lecture seule. Cependant, nous avons ici une “hard-limit” du modèle : SeaweedFS privilégiant la consistance à la disponibilité, ce dernier interrompt toute action d’écriture si le cluster n’est plus en état de valider l’ensemble des écritures voulues. Cependant, nous avons deux solutions de contournement, que nous allons évoquer : le changement de réplication temporaire, et la réplication asynchrone multi-cluster.
Note : Une option “de riche” serait d’avoir un troisième datacenter à disposition, et de conserver une réplication 100. Ainsi, si un datacenter
tombe, il est toujours possible de redonder la donnée comme demandé. Cependant, cette option a des limites, la première étant qu’en entreprise, on ne
sort pas un datacenter de terre aussi simplement que ça…
Changement de réplication temporaire
L’idée de cette solution est de temporairement changer la réplication configurée sur le cluster, afin de permettre aux utilisateurs d’écrire à
nouveau. Cette opération demande de redémarrer les nœuds master encore vivants (heureusement, on peut le faire l’un après l’autre, et donc ne pas
faire tomber tout le cluster). Afin de préserver un minimum de redondance, on peut jouer sur notre réplication pour demander à Seaweed de répliquer à
minima dans un autre rack ; par exemple en passant d’une réplication 100 à 010. Expérimentons cette possibilité.
A titre d’essai, je re-tombe “WAW-2”, et je tente de modifier la réplication en “001” : cela permet de demander aux deux serveurs restants sur “WAW-3”
de se synchroniser entre eux sur le même rack (pour garder une résilience), et ne plus attendre l’autre datacenter. Sur les 2 serveurs de volume, je
modifie le defaultReplication à 001, et je relance les nœuds 1 à 1 (pour éviter une full-downtime).
Mes 5Go de données (100 * 50Mo) s’écrivent alors en 4min04s, sans aucune erreur rclone !
Je rallume ensuite les noeuds de “WAW-2”. En listant les volumes, je peux voir le volume “77”, qui correspond à mon expérimentation, qui dispose d’une
réplication 001. Hors, maintenant que mon second datacenter est à nouveau disponible, j’ai envie de répliquer mes données sur celui-ci !

Figure 5 : La réplication en mode 001, ce qui n’est pas du tout notre target habituelle.
Pour cela, SeaweedFS va nous permettre de modifier, directement en ligne de commande, la réplication du volume, et de forcer le “rebalance” du cluster. Attention, durant cette opération, le volume passera en lecture-seule ! Il est donc essentiel de prévenir vos utilisateurs d’une telle opération.
Afin de redonner à notre volume affecté la bonne valeur, je lance un weed shell. Je commence par un lock, afin d’obtenir le verrouillage et d'
éviter qu’un autre utilisateur lance des actions d’administration pendant mes tâches.
Puis, je lance volume.configure.replication -volumeId 77 -replication 100, afin de modifier la réplication de mon volume actuellement créé.
Enfin, volume.fix.replication -force permet de lancer le rebalance. Attention à ne pas oublier le -force, sinon SeaweedFS ne fera qu’un dry-run !
Une fois l’opération terminée, je pense à unlock.
> lock
> volume.configure.replication -volumeId 77 -replication 100
> volume.fix.replication -force
volume 77 replication 100, but under replicated +2
replicating volume 77 100 from [fdaa:90af:7ed6:3cd0:164b:84c6:8809:7471]:8080 to dataNode [fdaa:90af:7ed6:3cd0:5fbd:840d:4aa0:d131]:8080 ...
volume 77 processed 130.00 MiB bytes
volume 77 replication 100 is not well placed [fdaa:90af:7ed6:3cd0:164b:84c6:8809:7471]:8080
deleting volume 77 from [fdaa:90af:7ed6:3cd0:164b:84c6:8809:7471]:8080 ...
volume 77 [fdaa:90af:7ed6:3cd0:164b:84c6:8809:7471]:8080 has 40 entries, [fdaa:90af:7ed6:3cd0:2d71:76d:ab0e:a357]:8080 missed 0 and partially deleted 0 entries
volume 77 [fdaa:90af:7ed6:3cd0:164b:84c6:8809:7471]:8080 has 40 entries, [fdaa:90af:7ed6:3cd0:5fbd:840d:4aa0:d131]:8080 missed 0 and partially deleted 0 entries
> unlock

Figure 6 : Notre volume est à nouveau en réplication 100 hourra !
Cette approche permet de garder une certaine souplesse dans la gestion de la donnée, tout en continuant à rendre le service pendant la panne. L’inconvénient est de devoir modifier la réplication manuellement, mais objectivement, êtes-vous à cela prêt lorsque vous perdez un datacenter complet ?
Réplication asynchrone multi-DC
Une autre option serait de changer totalement la philosophie de déploiement, afin de ne pas avoir un seul cluster sur deux datacenters, mais deux clusters ; un par datacenter. Cette philosophie est présentée dans la documentation de SeaweedFS, et présente l’avantage d’effectuer de la synchronisation asynchrone entre les datacenters.
Cependant, cela signifie qu’on abandonne la garantie de consistance en faveur de la disponibilité. C’est une approche envisageable selon votre besoin. Dans le cas que je souhaitais tester, l’absence de consistance de donnée n’était pas envisageable ; je n’ai donc pas poussé davantage cette option.
Performances en mode FUSE et WebDAV
Pour ce test, nous allons reprendre notre cluster en mode “nominal” (réplication cross-datacenter) sur WAW-2 et WAW-3. Je suis la documentation indiquée sur le wiki de SeaweedFS (FUSE, WebDAV).
Le client sera mon PC, connecté à une fibre 2.5Gbps. Le disque est un NVMe (Phison Electronics Corporation PS5021-E21 PCIe4). La vitesse d’écriture est de 2,4GBps, et celle de lecture de 4,2GBps.
Nous allons calculer le temps pour écrire 1Go de données aléatoires dans des blocs de 1Mo, 50Mo, et le temps requis pour les rapatrier. J’effectuerai également le test avec des données aléatoires en bloc de 4ko, mais avec moins de fichiers (pour éviter que cela me prenne la journée)
Montage FUSE
Pour démarrer un montage FUSE, il suffit de lancer sur son poste
./weed mount -filer=volumes.lab.forestier.re:8888 -dir=fuse/ -filer.path=/fuse-test -volumeServerAccess=filerProxy. Cette commande montera dans
./fuse/ de votre ordinateur le dossier /fuse-test du cluster SeaweedFS.
De là, je créé 3 dossiers depuis mon terminal : 4ko, 1Mo et 50Mo, pour stocker les fichiers correspondants. Puis, avec date et cp, je copie
les fichiers précédemment générés, et je récupère les temps d’exécution :
(Note : je suspecte fortement mon disque NVMe d’être limitant dans les tests à 4ko et 1Mo.)
- 4ko (22528ko dans 5399 fichiers) :
- Écriture : 16min13s (973s) ; soit 23.15ko/s
- Lecture : 4min25 (265s) ; soit 85.01ko/s
- 1Mo (1048612ko dans 1024 fichiers) :
- Écriture : 3min54s (234s) ; soit 4481ko/s (4,37Mo/s)
- Lecture : 1min12s (72s) ; soit 14564ko/s (14,22Mo/s)
- 50Mo (1075204ko dans 20 fichiers) :
- Écriture : 28s ; soit 38400ko/s (37Mo/s)
- Lecture : 46s ; soit 23374ko/s (22,82Mo/s)
- Copie du dépôt GitHub d’OpenBAO ( 372480ko dans 6063 fichiers) :
- Écriture : 17min49s (1069s) ; soit 348ko/s
- Lecture : 5min12s (312s) ; soit 1193ko/s (1.16Mo/s)
On constate que les performance en FUSE sont bien supérieures à celle en mode S3 ! Je suis presque frustré du test à 50Mo, car je pense que je suis limité par la bande passante publique du serveur (pour rappel, on l’avait estimé à 45Mo/s un peu plus haut). Étant donné que mon test se déroule le lendemain, on est dans une marge d’erreur probable.
Par ailleurs, je dois dire que je suis assez étonné de ces performances : le montage FUSE de Google Cloud Platform est environ 10 fois moins véloce, et supporte environ 10 fois moins de fonctionnalité : il faut saluer le travail de fond effectué par les développeurs de SeaweedFS, qui proposent un FUSE totalement POSIX-compliant, avec support des symlinks et autres joyeusetés ; là où même les hyperscalers ne se sont pas encore aventurés. Bref, c’est du solide !
Montage WebDAV
Mon filer étant déjà configuré pour exposer un endpoint WebDAV, j’ai juste besoin de le monter avec davfs2 :
sudo mount.davfs http://volumes.lab.forestier.re:7333/dav /mnt/dav, et je relance le même protocole expérimental (note importante : l’écriture
WebDAV est asynchrone ; je prend donc en compte le temps jusqu’à ce que la dernière opération d’écriture soit validée) :
- 4ko (4928ko dans 1000 fichiers) :
- Écriture : 5m23s (323s) ; soit 15.25ko/s
- Lecture : 1m32s (92s) ; soit 52.56ko/s
- 1Mo (1048612ko dans 1024 fichiers) :
- Écriture : 5m25s (325s) ; soit 3226ko/s (3.15Mo/s)
- Lecture : 3min21s (201s) ; soit 5216ko/s (5.09Mo/s)
- 50Mo (1075204ko dans 20 fichiers) :
- Écriture : 1m07s (67s) ; soit 16047ko/s (15.67Mo/s)
- Lecture : 46s ; soit 23374ko/s (22,82Mo/s)
Comme on peut le constater, WebDAV est systématiquement plus lent que le montage FUSE ; donc autant rester sur FUSE.
Stress test
Maintenant que nous avons joué avec SeaweedFS, il est temps de passer aux choses sérieuses ! Nous allons instancier 10 instances DEV1-S chez Scaleway, directement raccordées à notre VPC précédemment créé. Je modifie également la configuration des filers pour écouter désormais sur l’IP interne au VPC. Vous l’aurez compris, le but est de regarder la performance de notre système dans des conditions au plus proche du réel : nos clients SeaweedFS sont désormais sur le même réseau que notre baie de stockage, cela ressemble donc à un vrai réseau d’entreprise, où les VMs sont sur le même réseau que les baies de stockage.
Afin de préserver une isolation réseau réaliste, je n’expose à mes instances que les nœuds de filer, qui font intermédiaire vers les serveurs de volume.
Sur chaque machine, je créé 1024 fichiers de 1Mo (donc 1Go de données, soit 1048616ko), et 41 fichiers de 50Mo (donc 2050Mo de données, soit 2099212ko). Je monte ensuite sur chaque machine un montage FUSE, chacun vers un bucket séparé (pour simuler un usage conditions réelles, où chaque VM stocke des données qui lui sont propres, dans un bucket isolé des autres).
Avant de lancer ma copie simultanée, je le lance sur un noeud unique, pour avoir un point de comparaison avec le montage FUSE précédemment effectué sur mon ordinateur. Voici les résultats :
- 1Mo (1048616ko dans 1024 fichiers) :
- Écriture : 1m02 (62s) ; soit 16913ko/s (16.51Mo/s)
- Lecture : 19s ; soit 55190ko/s (53,89Mo/s)
- 50Mo (2099212ko dans 41 fichiers) :
- Écriture : 43s ; soit 48818ko/s (47,67Mo/s)
- Lecture : 33s ; soit 63612ko/s (62,12Mo/s)
La différence est incroyable ! Sur les fichiers de 1Mo, l’ordre est de 4x ; et sur du 50Mo, l’ordre est de 2x. Des performances beaucoup plus acceptables et cohérentes avec ce qu’on peut attendre d’un tel système.
Maintenant, il est l’heure du stress-test. Chaque nœud va envoyer ses 3Go de données, et les récupérer, et ce à 6 reprises (donc 3 * 10 * 6 = 180Go de données). Je vous met dans le tableau ci-dessus le temps du premier cycle écriture/lecture par machine, et la dernière
| Machine | stress-0 | stress-1 | stress-2 | stress-3 | stress-4 | stress-5 | stress-6 | stress-7 | stress-8 | stress-9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Première exécution - Écriture | 2min09s | 2min23s | 2min36s | 3min22s | 3min39s | 3min48s | 5min04s | 5min03s | 4min45s | 5min17s |
| Première exécution - Lecture | 3min52s | 3min24s | 3min24s | 3min18s | 3min03s | 3min04s | 2min08s | 1min49s | 2min11s | 1min31s |
| Dernière exécution - Écriture | 2min35s | 2min42s | 3min47s | 2min40s | 2min51s | 2min57s | 3min39s | 4min29s | 3min59s | 4min03s |
| Dernière exécution - Lecture | 1min39s | 1min32s | 1min53s | 2min20s | 4min03s | 3min48 | 3min40s | 3min07s | 3min27s | 3min12s |
Soit, en équivalent ko/s (en se basant sur un total de 3147828ko) :
| Machine | stress-0 | stress-1 | stress-2 | stress-3 | stress-4 | stress-5 | stress-6 | stress-7 | stress-8 | stress-9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Première exécution - Écriture | 24401ko/s soit 23.82Mo/s |
22012ko/s soit 21,49Mo/s |
20178ko/s soit 19,70Mo/s |
15583ko/s soit 15,21Mo/s |
14373ko/s soit 14,03Mo/s |
15133ko/s soit 14,77Mo/s |
10354ko/s soit 10,11Mo/s |
10388ko/s soit 10,14Mo/s |
11045ko/s soit 10,78Mo/s |
9930ko/s soit 9,69Mo/s |
| Première exécution - Lecture | 13568ko/s soit 13.25Mo/s |
15430ko/s soit 15,06Mo/s |
15430ko/s soit 15,06Mo/s |
15898ko/s soit 15,52Mo/s |
17201ko/s soit 16,79Mo/s |
17107ko/s soit 16,70Mo/s |
24592ko/s soit 24,01Mo/s |
28879ko/s soit 28,20Mo/s |
24029ko/s soit 23,46Mo/s |
34591ko/s soit 33,78Mo/s |
| Dernière exécution - Écriture | 20308ko/s soit 19.83Mo/s |
19431ko/s soit 18,97Mo/s |
19673ko/s soit 19,21Mo/s |
19673ko/s soit 19,21Mo/s |
18408ko/s soit 17,97Mo/s |
17784ko/s soit 17,36Mo/s |
14373ko/s soit 14,03Mo/s |
11701ko/s soit 11,42Mo/s |
13170ko/s soit 12,86Mo/s |
12954ko/s soit 12,65Mo/s |
| Dernière exécution - Lecture | 31796ko/s soit 31,05Mo/s |
34215ko/s soit 33,41Mo/s |
26904ko/s soit 26,27Mo/s |
22484ko/s soit 21,95Mo/s |
12954ko/s soit 12,65Mo/s |
13806ko/s soit 13,48Mo/s |
14308ko/s soit 13,97Mo/s |
16833ko/s soit 16,43Mo/s |
15206ko/s soit 14,84Mo/s |
16394ko/s soit 16,01Mo/s |
On constate qu’en règle générale, on a des performances maximales et minimales sur chaque segment pouvant aller du simple au double : cela s’explique car les machines en tout début ou en toute fin sont privilégiées, puisque leurs processus démarre quelques secondes avant/après tout le monde. Voici les écarts relevés :
- Première écriture : min. 9,69Mo/s, max. 23.82Mo/s
- Première lecture : min. 13.25Mo/s, max. 33,78Mo/s
- Dernière écriture : min. 11,42Mo/s, max. 19,83Mo/s
- Dernière lecture : min. 12,65Mo/s, max. 33,41Mo/s
La notion de temps de lecture/écriture en O(1) semble se confirmer : l’écart entre les performances de la première et de la dernière
lecture/écriture ne sont pas significatifs.
Il est également à noter que nous arrivons ici probablement sur une limite des SSD des serveurs Scaleway (qui sont, pour rappel, des serveurs à 7 centimes de l’heure, pas de quoi rougir donc). En effet, au cours de la période d’écriture/lecture, les machines n’ont jamais atteint leurs limites de CPU/RAM : Des crêtes à 25% de CPU ont été observées sur les nœuds de stockage ; les masters sont eux restés impassibles. Je met en capture ci-dessous une usage en pic d’écriture (sur la dernière exécution), et 5 secondes après la dernière lecture.
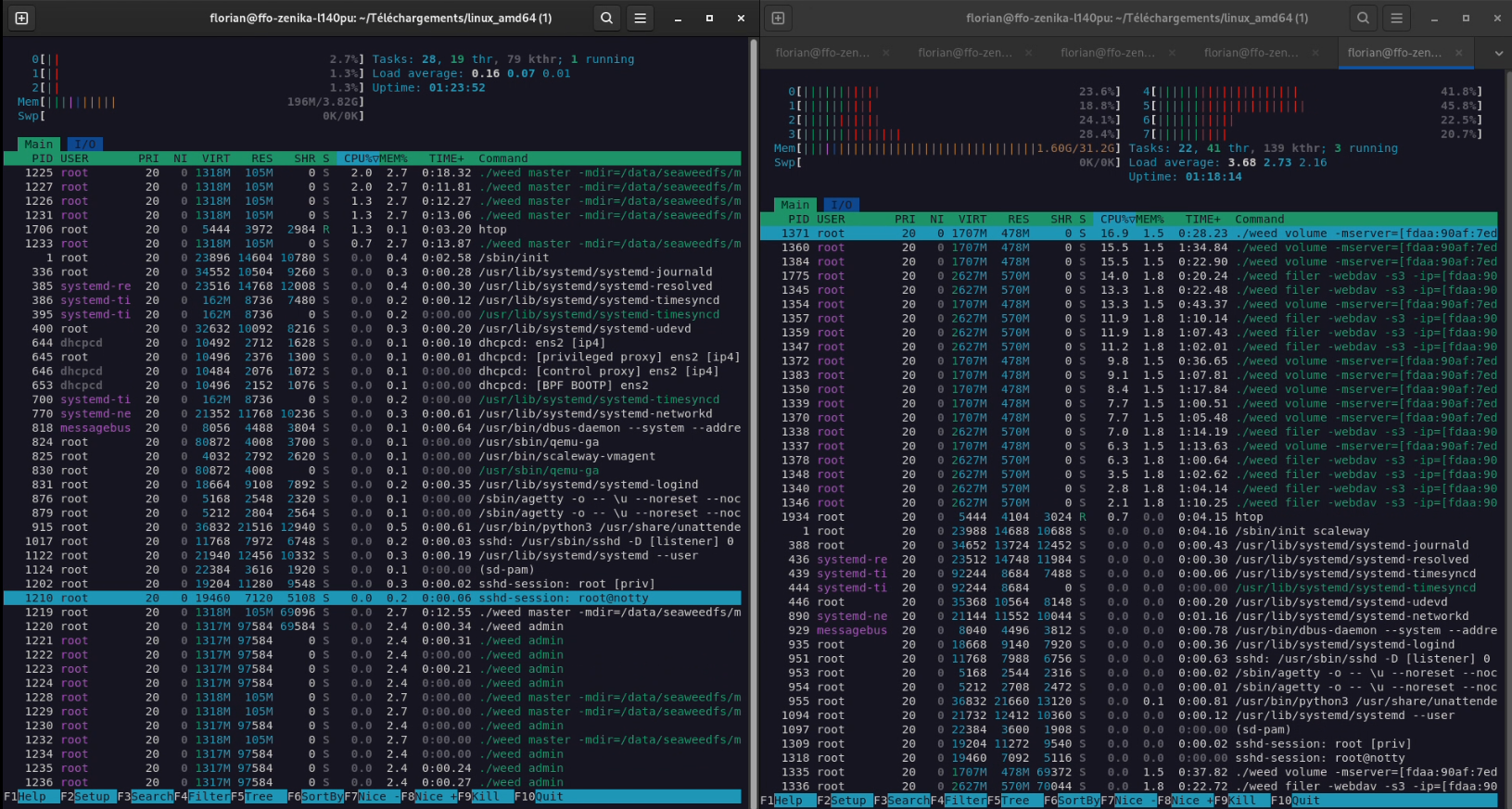
Figure 7 : Charge du cluster en pleine écriture. A gauche le nœud master actuellement “manager” ; à droite, un nœud de stockage.
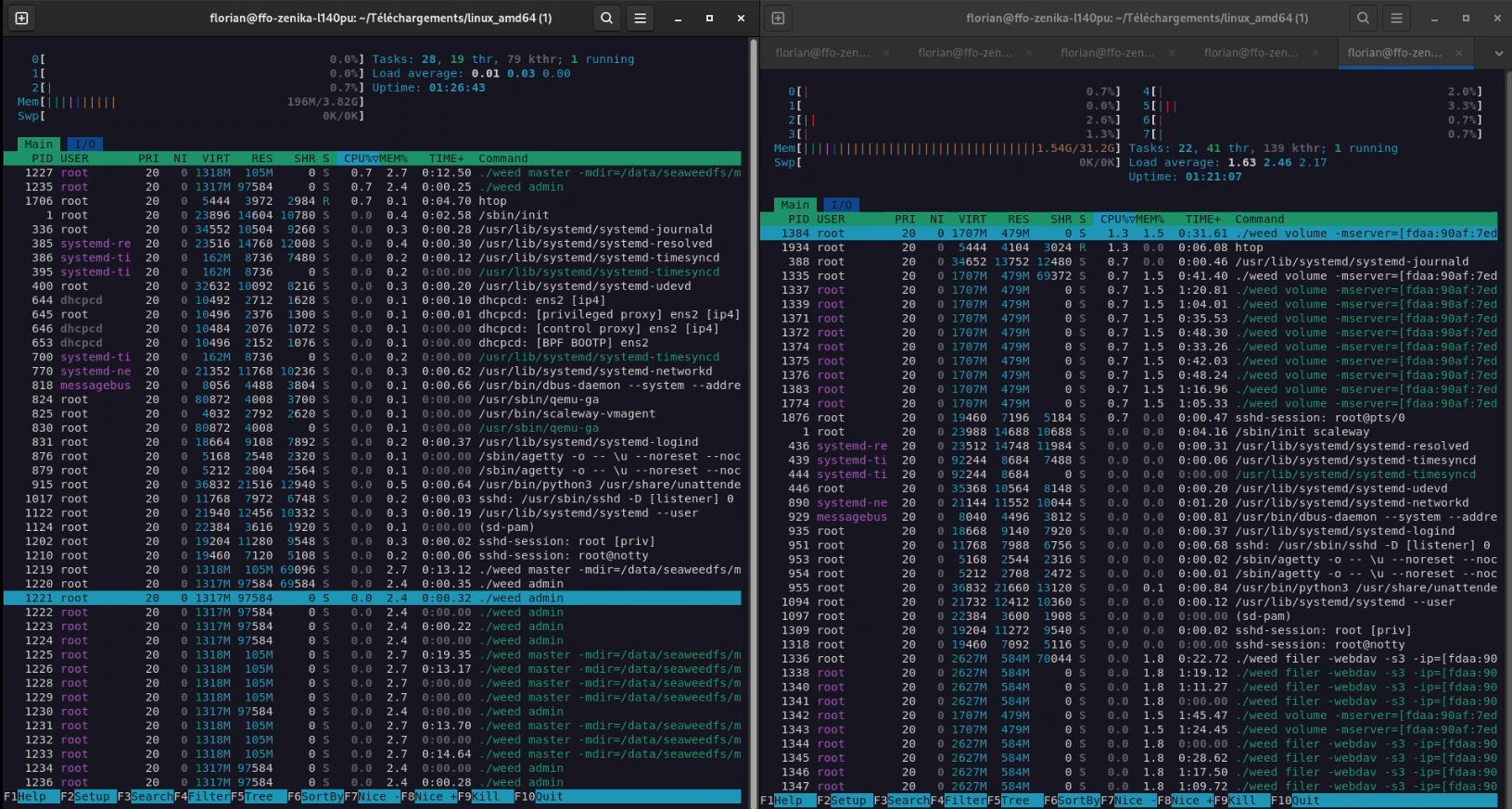
Figure 8 : Charge du cluster 5s après la dernière lecture. A gauche le nœud master actuellement “manager” ; à droite, un nœud de stockage.
En tout cas, le stress-test est passé haut la main : le cluster encaisse sans mal 180Go de données ingérées en tout juste 20 minutes, avec 10 clients connectés simultanément en train d’effectuer des actions très intensives.
Kubernetes CSI
J’installe le CSI directement fourni par les mainteneurs de SeaweedFS (disponible ici).
Attention, dans le fichier .yml, la variable SEAWEEDFS_FILER est présente deux fois, il faut donc bien la modifier à ces deux endroits.
L’installation ayant lieu dans un minikube dédié à cet usage, je rencontre un problème de réseau indisponible : en effet, Minikube ne supporte pas IPv6. Je me connecte donc sur un nœud volume, et je relance le filer avec une IPv4 publique, afin de corriger le soucis.
Je lance ensuite ma demande de claim :
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: claim-test
spec:
storageClassName: seaweedfs-storage
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
La StorageClass va immédiatement créer le PersistentVolume correspondant à notre claim, et le volume devient “Bound” et prêt à l’emploi. That’s it !

Figure 9 : Ressources crées dans Kubernetes

Figure 10 : Le PersistentVolumeClaim apparaît bien dans SeaweedFS comme un bucket dédié, automatiquement généré.
En usage, les performance sont similaires à celles obtenues en FUSE. Rien d’exceptionnel donc, mais parfaitement utilisable pour des usages non-intensifs. Autrement dit : ne mettez pas une base de données dessus ! (même si normalement, on ne met jamais une BDD dans Kube, n’est-ce pas ?)
Conclusion et limitations
En conclusion, nous pouvons tout de même affirmer que SeaweedFS est un projet réellement prometteur et qui permet d’obtenir facilement un système résilient, fiable, extrêmement tolérant à la panne, tout en restant simple à administrer. C’est assez rare pour le noter ; et c’est exactement le genre de software que j’aime : philosophie KISS en tête, tout en restant flexible et puissant. Bref, une sacrée prouesse, et je n’ai qu’une envie : le pousser encore plus loin, en conditions réelles !
Car, même si ce test est (à mon sens) suffisamment complet pour se faire une opinion assez réaliste de SeaweedFS - opinion positive, cela dit en passant -, il faut être bien conscient des limitations de ce genre de tests : nous étions sur un usage faible par rapport à un usage " entreprise-grade", à l’échelle du Go (et pas du To). Beaucoup de fonctionnalités n’ont pas été testées : backup/restore, tolérance à la corruption, réplication asynchrone, etc. Enfin, je n’ai pas passé de temps à fine-tuner le cluster (car chaque composant dispose d’un fichier de configuration assez complet pour configurer en détail le comportement du cluster). Je pense donc qu’il est possible, sans trop de mal, d’obtenir des performances bien supérieures à mes résultats sans grosse difficultés. Ce billet de blog doit vraiment être pris comme une découverte de l’outil, de ses possibilités et de ses limites, et non pas comme d’un benchmark complet et exhaustif de la solution.
Les performances en lecture/écriture peuvent paraître faiblardes : il ne faut cependant pas oublier que mon lab est une infra de test, sur des serveurs à très bas coût, qui ne sont pas prévus pour du stockage. Prenez deux véritables baies de disque, avec du SSD/NVMe performant et capable d’effectuer plusieurs lectures/écriture en simultané, et je pense que les performances vont s’envoler. Le hardware me limite ici, mais il ne faut pas oublier que c’est du lab sur des deniers personnels. Si vous avez des baies de disque à disposition, n’hésitez pas à me communiquer vos benchmarks !
J’ai effectué des benchs plus basiques (voir “Annexe - weed benchmark” ci-dessous) avec des EM-A610R-NVME, plus véloces en termes d’I/O. Les tests
montrent une légère amélioration des performances, malgré une optimisation côté Seaweed totalement absente (une fois de plus : je n’ai rien
fine-tuné). Bref, il y a sûrement un gros potentiel d’amélioration.
Quoi qu’il en soit, pour moi, SeaweedFS, c’est approuvé ; et comme qui dirait : “y’a plus qu’à”.
Annexe - Et l’usage système dans tout ça ?
Vous noterez que tout du long de cet article de blog, je n’ai pas parlé d’usage CPU/RAM (sauf sur la partie “stress-test”). C’est dû à une raison toute simple : Même lors des actions de rebalancing ou d’écriture intensive, je n’ai jamais vu mes serveurs (master ou volume) dépasser les 10% d’usage CPU ou le giga-octet de RAM utilisé. De quoi voir venir de manière très (mais alors, très) sereine l’augmentation d’usage d’un cluster production grade.

Figure 11 : L’usage d’un node master, en activité.

Figure 12 : L’usage d’un node volume, en activité.
Annexe - Coût & bilan carbone
Au cours de ce lab, j’ai utilisé de manière très intensive les ressources de Scaleway et, dans une moindre mesure, les ressources de Hetzner. Côté Hetzner, ma facturation s’est établie à 0,18€ sur la période des labs. Côté Scaleway, les frais ont été un peu plus importants (compte-tenu que 90% des tests ont été réalisés dessus). Les frais pour mon lab s’établit à 10,12€. Au total donc, le lab m’aura donc coûté 10,30€. Un montant dérisoire vu la quantité d’infra provisionné : 10 machines de stress-test, 3 contrôleurs, 4 baremetals de stockage, un VPC… Bref, je suis satisfait de ma gestion FinOps.
D’un point de vue carbone, Scaleway fournit l’empreinte environnementale des projets Cloud sur sa console. Celle-ci indique, à la fin du projet, une empreinte de 2,1kg de CO2 émis, soit l’équivalent d’un trajet en voiture de 11km. Cette empreinte est largement dégradée par mon utilisation de la région de Varsovie (qui utilise une électricité fortement carbonée). Malheureusement, les régions de Paris et Amsterdam ont un énorme défaut (qui m’a fait tourner en bourrique au début de mes essais) : Les baremetals à l’heure sont des instanciations de serveurs “Dedibox” classiques d’Online.net. Pour une raison obscure mais valide, ces serveurs n’ont pas le même fonctionnement réseau. J’ai donc eu de multiples problèmes d’instanciation lors de l’adressage IPv6, des retours aberrants du provider OpenTofu (avec notamment… 8 IPv6 rattachées à chaque dédié), sans compter le fait que chaque serveur mettait plus de 25 minutes à démarrer (contre 7min sur Varsovie)… J’ai donc, à regret, utilisé WAW-2 et WAW-3.
Enfin, dernier point positif du monitoring côté Scaleway : Je suis en mesure de vous donner le temps d’exécution du lab ; puisque j’ai utilisé 2668 minutes de baremetal Scaleway. Compte-tenu que mon infra était basée sur 4 nœuds, cela signifie que le lab a été actif 667 minutes, soit 11h07min d’expérimentation.
Cela permet de remettre en perspective les 10,12€ de consommation : 24h de run coûterait 21,84€, soit 677,30€ par mois sur une infra active 24/7… Bref, pensez à coupez vos ressources cloud !
Annexe - weed benchmark
Fourni à titre indicatif ; voici le résultat des weed benchmark sur le cluster. Ces benchs semblent confirmer que mes serveurs à disposition ont
des I/O assez limités malgré un gros débit de lecture/écriture. L’écart de performance est impressionnant selon la taille du fichier ; mais je ne
dispose pas d’une infra plus “performante” que celle décrite dans le billet.
Pour éviter de rallonger encore ce billet de blog, les benchmarks sont sur GitHub.