Mon infra perso (édition 2025)
This article is also available in English.
En début d’année, j’ai décidé de faire le ménage dans mon infra maison (que j’utilise pour stocker/partager des documents, gérer mes mots de passe, héberger ce blog, etc). Au fil des années, cette infra était devenue de plus en plus complexe (car de plus en plus de services), et surtout, je n’avais pour ainsi dire jamais le temps de faire mes changements proprement : j’étais dans une approche YOLO totale, avec un GitLab 15 exposé aux quatre vents, des performances abyssales sur la moitié de mon infra (👋 mon Nextcloud qui a survécu un an avec 500Mo de RAM et un demi CPU), une multiplication des serveurs affolante, une stratégie de backup discutable… Bref, c’était le bordel.

Si même Hubert le dit…
Juste pour le fun, et vous donner le niveau de perdition du navire : J’utilisais 3 serveurs dédié (des Scaleway Dedibox Start-2-L), 2 VPS chez BeYs, et tout ce bazar joyeusement relié par un VPN histoire de faire transiter de la data dedans. J’avais des bouts à gauche, d’autres à droite, des backups croisés sur ces deux infrastructures, des montages GlusterFS… Pour au final une utilité presque inexistante ! Pour rappel, j’héberge uniquement mes services personnels dessus : Nextcloud, VaultWarden ; bref, rien qui ne justifie une telle usine à gaz.
Mes services étaient (à 90%) déployés avec du Ansible, et des containers Docker. J’avais tout dans un bon gros playbook.yml des familles de 1800
lignes ; et bien sûr pas de tag. Autrement dit, quand je voulais mettre à jour Traefik, je mettais à jour… Toute l’infra. Et en général, ça cassait
partout. 😎
Mais heureusement pour mon infra (et ma santé mentale), le début d’année m’a permis de mettre à nouveau mon nez dans tout ça, et la décision fût radicale : “Monsieur, faut tout couper”. Non seulement car c’était un bordel monumental qui m’aurait mis des heures à démêler, mais aussi car les performances de mes machines étaient trop mauvaises. Je me suis donc mis en quête d’un nouveau “bon gros dédié” qui pourrait accueillir toute mon infra sans broncher. Oui, c’est un SPOF, mais je n’ai pas non plus 100 balles par mois à mettre dans ce genre de choses ; alors on fera avec.
Et, coup du hasard, OVHCloud proposait des promos sur leur gamme “So You Start” (c’est les serveurs reconditionnés d’OVH mais qui sont quand même mieux lotis que les Kimsufi). La fiche technique est vraiment sympatoche pour un prix très raisonnable (40€ par mois), alors je saute le pas. (A la base, je voulais prendre 3 KS-A à 5€ par mois et monter un cluster Kubernetes dessus, mais la légende raconte que le dernier a avoir réussi à en commander un y est arrivé avant l’introduction en bourse d’OVH, vers 2022).
J’ai donc jeté mon dévolu sur un SYS-1 en version disque SATA pour avoir une belle capacité (vous saviez que des .RAW d’un Canon EOS 90D, ça
bouffe 50Mo par image ?). Dans le détail, voici un peu les perfs :
- Un Xeon-E 2136 (6 cœurs, 12 threads) - 3.3GHz/4.5GHz
- 32Go de RAM à 2666MHz
- 8To de disque, en 2*4To Soft RAID
- 500Mbps entrant/sortant illimité
- Une IPv4 + Un /64 en IPv6 (comme ça, le jour où je m’y mettrai, je serai dual-stack)
Pourquoi ne pas avoir monté tout ça en local ?
Pour plusieurs raisons :
- Je vis en appartement, et monter une server-room c’est un peu compliqué en l’état actuel des choses ;
- Je considère qu’un fournisseur sera toujours plus fiable que moi, n’ayant pas de climatisation, pas de redondance, pas de PCA, pas de surveillance 24/7, bref, vous avez compris ;
- J’ai pas envie de m’embêter avec Orange et leur merveilleuse livebox et me retrouver à passer mes week-ends à faire du réseau pour tenter de faire tomber en marche des trucs. On ne parlera même pas de DynDNS et compagnie.
- En bref : c’est super si vous avez le temps et moyen de le faire, mais dans mon cas, c’est non !
Mon infra, elle fait quoi ?
Mon infra, elle me sert pour plein de choses au quotidien ! Elle héberge :
- Mes fichiers, mes agendas et mes contacts (avec un serveur Nextcloud & Collabora) ;
- Mon code source (avec un Gitlab et son petit runner) ;
- Des sites web statiques (mes présentations, ce blog, le site des cours pour mes étudiants, etc) ;
- Mes mots de passe (VaultWarden) ;
- Mon serveur mail (c’était peut être pas la meilleure idée mais c’est pas le sujet) ;
- Un VPN pour sécuriser ma connexion quand je suis en déplacement / sur WiFi public ;
- Un n8n pour effectuer ma veille techno et quelques tâches du style ;
- Divers petits projets “de bidouille” ;
- Et un petit serveur Minecraft de temps en temps.
Plein de choses, certes, mais au final rien d’extrêmement gourmand en ressources. Mon nouveau dédié chez OVH devrait donc largement faire l’affaire !
C’est parti ? C’est parti !
Une fois mon serveur OVH reçu, je commence par installer une Alpine Linux. C’est un énorme avantage de OVH : sur la gamme dédié, vous avez un mode " Bring Your Own Image", qui vous permet de vous débrouiller comme un grand : on se connecte à l’IPMI, on démarre le disque virtuel qui contient notre ISO, et zou, c’est parti. Quelques dizaines de minutes plus tard, me voilà avec une Alpine toute fraîche et un serveur entier à configurer.
Compte-tenu du nombre de services à faire tourner, Docker sonne comme une évidence. Cependant, j’aimerai avoir un peu plus de fonctionnalités que ce
que me permet nativement Docker ; notamment en pouvant mettre à jour mes services sans devoir les couper durant la mise à jour ; et surtout disposer
d’un rollback automatique si quelque chose échoue - j’en ai assez de passer 4h sur un problème qui devait me mettre 2 minutes. Par confort et esprit
de simplicité, je pars sur un Docker Swarm mono-nœud. Le choix est purement pragmatique : je maîtrise très bien cette techno, elle matche mon besoin,
tout en gardant une installation Docker ultra simple (car Docker est disponible directement dans les paquets apk sur Alpine, donc apk install docker
et paf, c’est parti). Bref, je ne vais pas encore vous rabattre les oreilles avec Swarm, puisque
j’ai déjà fait un article sur celui-ci.
Bien, maintenant que j’ai un mono-nœud Swarm prêt à accepter du trafic, je commence à déployer les services essentiels pour tout le reste : Traefik, swarm-cronjob, et rclone.
- Traefik va s’occuper de relayer mes requêtes vers les bons containers selon l’host demandé ;
- swarm-cronjob permet d’exécuter des tâches cron dans des services Swarm, ce qui me facilite la vie ;
- rclone me permet de faire mes backups.
Et, pour me simplifier encore plus la vie, je monte tout cela à travers un bon vieux playbook Ansible. J’en profite pour automatiser quelques
configurations importantes : les comptes utilisateurs (car alpine en utilisateur, c’est le mal !), l’installation de Docker, les ouvertures réseau &
le firewall, ainsi que l’authentification à mon registry Docker privé (pour pouvoir récupérer des images). Comme je n’ai pas encore mon VaultWarden de
déployé, j’utilise ansible-vault en gestionnaire de secret. C’est pas idéal, mais on a connu pire. Le playbook est
disponible dans le dossier Bootstrap/ du dépôt GitHub.
Maintenant, il ne me reste plus qu’à déployer mes services. Pour cela, je créé sur mon GitLab un projet par outil à déployer, et je met à l’intérieur la même structure : un playbook Ansible qui me permet de démarrer un service Swarm.
|- Mailserver/
|- playbook.yml
|- README.md
|- requirements.yml
|- files/
|- [...]
|- inventories/
|- servers
|- tasks/
|- backup.yml
|- install.yml
|- prepare.yml
|- vars/
|- vars.yml
|- Gitlab/
|- [...]
Pour récupérer les secrets, j’utilise un bout de code qui me permet de faire la jonction entre mon VaultWarden et la CI GitLab, grâce au
CI_JOB_TOKEN. Je ne publie pas (pour l’instant) ce code car il est vraiment horrible et c’est une très mauvaise idée de l’utiliser (personnellement,
je m’en sers uniquement en local sur le serveur, il n’est pas exposé).
Je gère mes versions avec des tags sur GitLab. Ainsi, un tag “18.0.1” sur le projet GitLab lancera automatiquement la CI permettant de mettre à jour mon serveur sans manipulation manuelle.
Ces playbooks sont disponibles dans leurs dossiers respectifs sur le dépôt GitHub.
Maintenant que j’ai mon infra et l’ensemble de mes services déployés “as-code”, j’ajoute des backups. Une fois de plus, vous l’aurez compris, les backups vont tourner dans des services “job” de Docker Swarm. J’ai déjà fait un billet de blog sur les sauvegardes, alors je vous laisse consulter l’article sur le sujet si vous voulez le détail ! Bien entendu, mon dédié étant chez OVH, j’ai pris la précaution d’effectuer mes sauvegardes chez un autre provider. On est jamais trop prudents !
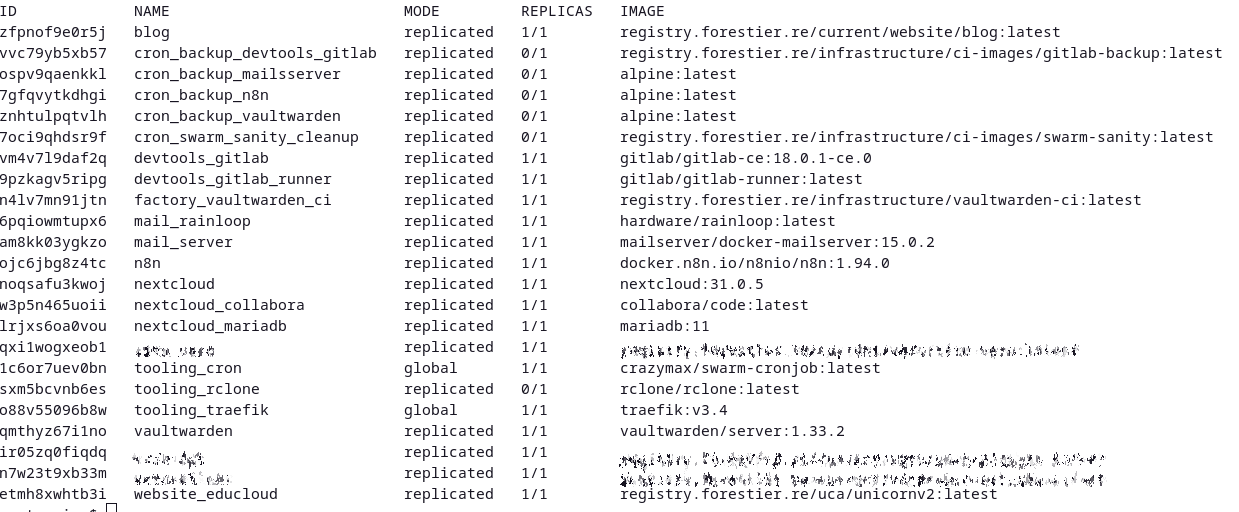
La liste de mes services déployés
Et maintenant ?
Maintenant, mon infra tourne enfin sur quelque chose de viable, maintenable et surtout simple. Je me suis libéré une assez grosse charge en ré-automatisant toute mon infrastructure, et mon approche me permet de conserver une gestion quotidienne facile. Il me reste cependant à remettre en place du monitoring : Je n’ai pas eu le courage de faire ça au départ ; et je pense ré-utiliser un de mes VPS pour le faire (car s’auto-monitorer, c' est pas du plus fiable).
Maintenant, une question reste entière : Comment faire en sorte à automatiser les mises à jour de mon infra, et ainsi ne même plus avoir à créer de tags à la main dans GitLab ? Et bien, cela, ce sera pour la prochaine fois… 😉