Gérer ses backups avec rclone & Scaleway Glacier
This article is also available in English.
Lorsque j’ai reconstruit mon infrastructure “maison” fin 2024 (car mes dédiés de 2015 commençaient à légèrement arriver en fin de vie), j’ai décidé de prendre le temps de réfléchir à une véritable stratégie de backup. En effet, les sauvergardes ont longtemps été un (des nombreux) parents pauvres de mon infra : j’effectuais chaque nuit une sauvegarde complète de mes données sur un des serveurs FTP inclus dans l’offre “Dedibox” de Scaleway. Pour résumer rapidement mon ancien système de backup, on peut noter que, dans les points positifs, ça marchait (et c’est déjà pas mal). Dans les points négatifs… Pêle-mêle, c’était lent, c’était atroce en terme d’optimisation de l’espace (140Go chaque nuit, youhou !), je ne pouvais pas récupérer un fichier ou dossier en particulier. Pour résumer, c’était bien rigolo comme moyen de fonctionner, mais ça sentait bon les années 2000. On passera sur les notions basiques de sécurité ; la connexion FTP n’étant même pas chiffrée. 🥴
Bref, nous sommes fin 2024, et j’ai besoin de trouver une nouvelle solution de backup. D’autant plus que mon infrastructure commence à avoir d’autres usages : en effet, plusieurs proches commencent à utiliser mon stockage pour stocker pas mal de fichiers (notamment les sauvegardes de vieilles photos numériques, et des RAW immenses de 40Mo).
Au début, je tente de garder une approche assez “conservatrice” pour mes sauvegardes ; et je me met en quête d’un stockage “bloc” en libre-service (
type FTP ou similaire avec SCP ou autre). Je tombe notamment sur les storage box d’Hetzner mais je
suis dubitatif sur les performances ; et le fait de continuer à faire mes backups “à l’ancienne” à grand coup de .tar.gz me déprime un peu.
Ayant été un très bon client de Scaleway sur la dernière décennie, j’avais entendu parler de leur stockage objet et notamment de leur offre " Glacier", le fameux stockage situé dans un bunker sous Paris. Et j’avoue que j’avais très envie d’essayer de jouer un peu avec ! D’une part car c’est un provider Français et que la souveraineté me tiens à coeur, d’autre part car j’ai beaucoup manipulé du stockage objet dans mon ancien emploi, et que je trouvais la technologie parfaitement appropriée.
C’est quoi, du stockage objet ?
Pour résumer en très simple et en très bref, du stockage objet, c’est simplement un espace de stockage que vous accédez via une API HTTP. Cela vous permet d’accéder et de gérer vos fichiers sans avoir à effectuer un point de montage, de gérer l’extension d’un espace disque, ou même le type du système de fichiers. En contrepartie, bien entendu, les performances seront moindres. Si vous tentez de lancer un serveur de jeu Counter-Strike sur un stockage objet, spoiler, ça va laguer !
C’est un concept qui a été inventé par Amazon (avec AWS), sous le doux nom de Amazon S3. C’est, pour l’anecdote, le premier service “cloud” qui a vu le jour ; puisque c’est avec S3 qu’AWS a débarqué sur le marché en 2006 ! Il faudra attendre près de 3 ans pour que la concurrence s’établisse. C’est d’ailleurs pour cela que la majorité des Cloud Providers qui fournissent un service de stockage objet parlent souvent d’API “compatible S3” : comme tout le monde c’était mis à utiliser Amazon S3, les autres Cloud Providers ont décidé de prendre la même implémentation pour leurs propres services de stockage objet, afin d’être compatible dès le départ avec les divers outils du marché. Scaleway ne fait d’ailleurs pas exception à la règle.
Figure 1 : La description du stockage objet de Scaleway.
Le stockage objet étant réputé comme étant très simple à utiliser, très peu coûteux par rapport à du bloc storage, et exposant directement ses fichiers sur le Web via HTTP, c’est un moyen de stockage très prisé pour héberger des fichiers statiques (images, vidéos, etc) ! Par exemple, les skins des joueurs de Minecraft sont stockés dans du S3. Sans même vous en rendre compte, vous êtes déjà un utilisateur d’un système de stockage objet ; qu’il soit d’Amazon ou autre.
D’ailleurs, si vous le souhaitez, sachez que vous pouvez installer votre propre serveur de stockage objet à la maison ! De nombreux projets proposent en effet une implémentation, compatible S3 ou non : OpenStack (avec Swift), SeaweedFS, entre autre.
Afin de conserver une structure dans vos fichiers, il est tout à fait possible de créer des dossiers et des sous-dossier (et des sous-sous-dossier, bref, vous avez compris) pour structurer vos données. Par ailleurs, un espace de stockage objet s’appelle un bucket. Chaque bucket va, selon le cloud provider, disposer de caractéristiques propres (nombre de réplication, type de stockage, etc). D’ailleurs, pour l’écrasante majorité des Cloud Providers, la facturation du stockage objet s’effectuera au bucket.
C’est quoi, Scaleway Glacier ?
Glacier, c’est la solution de “cold-storage” de Scaleway. En effet, chez les Cloud-Providers, on distingue la donnée selon le temps d’accès qu’on souhaite avoir :
- Le hot-storage va concerner l’ensemble des données dont vous avez besoin d’accèder très fréquemment, et en peu de temps (quelques millisecondes). Si on reprend notre exemple des skins Minecraft de tout à l’heure, on est totalement dans cette définition : les skins doivent charger rapidement, à tout moment.
- Le cold-storage va concerner les données qui peuvent être déchargées après leur envoi. Ici, on va retrouver les données de backups, les données liées à des raisons légales, etc. Ce stockage est en général beaucoup moins coûteux, car contrairement au données en hot-storage, elles ne sont pas conservées sur des disques, ni répliquées en temps-réel : elles sont indexées puis stockées sur des supports plus durables, en règle générale du stockage sur bande. Cette manière de faire permet de garder des données en sécurité à moindre coût, mais empêche bien entendu la lecture en temps-réel. Lorsque vous souhaitez accèder à vos données, il faudra attendre (en général, plusieurs heures) qu’un petit robot aille chercher la bande, la lise, et vous mette à disposition les fichiers.
Vous l’aurez compris donc, nous allons parler ici de cold-storage : je considère, pour un usage personnel, totalement acceptable d’avoir un délai de quelques heures de remise à disposition de mes fichiers. Après tout, je gère un Nextcloud à la maison, pas une multinationale.
C’est quoi, rclone ?
rclone est un outil conçu pour faciliter l’utilisation de nos fameux object storages, en offrant une interface en ligne de commande unifiée ; et de nombreuses capacités de synchronisation automatique entre votre infrastructure “réelle” (VM, dédié, container, etc) et votre Cloud Provider. Le projet GitHub décrit le projet comme étant “rsync, pour le stockage cloud”. Notamment, rclone permet de copier et de synchroniser des fichiers entre votre machine et votre Cloud Provider, mais également de monter votre object storage en tant que volume (même si les performances seront, très probablement, atroces), et d’agir comme serveur (HTTP, WebDAV, SFTP et même DLNA) pour vos fichiers locaux (ou distants !). Bref, c’est une véritable boite à outil pour quiconque utilise de stockage objet.
Le projet est disponible sur GitHub, sous licence MIT.
Sauvegarder nos données
La partie Scaleway
Maintenant que les présentations sont faites, il est temps de mettre en place notre sauvegarde !
La première étape à faire est de nous créer un bucket. Dans la Console Scaleway, allez dans “Storage => Object Storage”, puis cliquez sur “Créer un bucket”.
On pourrait aussi faire ça avec un petit coup d’OpenTofu, mais la mise en place est beaucoup trop longue pour notre exemple, donc je vais au plus simple.
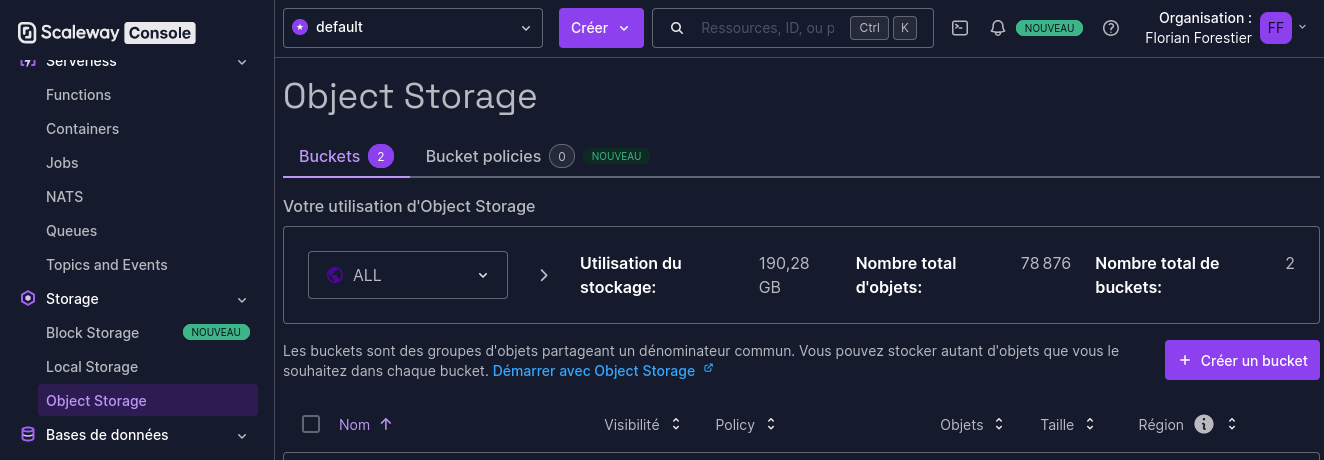
Figure 2 : La console Scaleway.
Créez ensuite votre bucket avec la configuration que vous préférez. A titre personnel, voici ce que j’utilise comme paramètres :
- Région : Paris
- Visibilité du bucket : Privé - note : si vous définissez la visibilité sur Public, vous pourrez accèder à vos fichiers, sans authentification, via HTTP. Ce n’est très probablement pas ce que vous voulez pour du backup de données…
- Cas d’usage : Sauvegarde et archivage (ça n’a aucun intérêt, c’est pour les stats de Scaleway)
- Versioning du bucket : Tout dépend de si vous voulez garder plusieurs versions de vos fichiers ou non. Personnellement je l’active, mais gardez en tête que cette option est facturée…
- Essai gratuit : Désactivé
Maintenant que votre bucket est créé, vous pouvez créer des règles de cycle de vie. Ces règles vont vous permettre de supprimer automatiquement les données trop vieilles pour être conservées. Par exemple, vous pouvez définir qu’une donnée qui n’a pas été accédée depuis 2 ans ne représente plus aucune valeur, et peut être supprimée. Cela vous permet de garder le contrôle sur votre stockage utilisé, et donc votre facture. Ces règles de vie s’appliquent par défaut sur l’ensemble des objets du bucket, mais vous pouvez également définir des filtres en vous basant sur les noms de fichiers ou les métadonnées. Vous pouvez également automatiser le passage d’un fichier de hot-storage à cold-storage s’il n’a pas été accédé depuis longtemps, ce qui vous permet d’avoir une optimisation automatique de la localisation de vos fichiers selon leur usage réel !

Figure 3 : Un cycle de vie Scaleway.
Ici par exemple, je définis que les fichiers datant de plus de 30 jours, et que les envois non-terminés depuis 2 jours doivent être supprimés du bucket. Bien entendu, à vous d’adapter selon la sensibilité de vos fichiers, et de la rétention que vous souhaitez y appliquer !
Maintenant que notre bucket est configuré, nous avons besoin de générer une clef d’API. Dans le menu “Organisation” en haut à droite, cliquez sur " Clés API" ; puis “Générer une clé API”. Voici les paramètres à indiquer :
- Porteur de la clé : Moi-même
- Cette clé API sera-t-elle utilisée pour Object Storage ? : Oui, et garder le projet “Défaut” (sauf si vous l’avez modifiée).
Conservez ensuite très précieusement la clé et le secret fourni ; vous ne pourrez pas les retrouver après ! Maintenant que nous sommes prêts côté Scaleway, place à rclone.
Configurer rclone
Pour notre rclone, je vais utiliser un bon vieux container Docker, et crontab. Vous l’aurez compris, nous sommes très loin d’une configuration sexy (on aurait pu faire une cron Kubernetes ou autre), mais une fois de plus, je tente de garder l’article simple et clair. N’hésitez pas à adapter ce que je vous présente à votre stack. Par exemple, chez moi, ça tourne dans un Docker Swarm avec du swarm-cronjob.
Commençons par créer notre fichier /srv/rclone.conf :
[NOM_DU_BUCKET]
type = s3
provider = Scaleway
access_key_id = VOTRE_ACCESS_KEY_COMMENÇANT_PAR_SCW
secret_access_key = VOTRE_SECRET_KEY
region = fr-par
endpoint = s3.fr-par.scw.cloud
acl = private
storage_class = GLACIER
Remplacez les trois placeholders par les valeurs obtenues précédemment. Dans ce fichier, nous indiquons à rclone comment nous authentifier à Scaleway, quel type de stockage utiliser, et le nom de notre bucket. Si vous avez modifié certains paramètres (région, droits d’accès), n’hésitez pas à modifier. La documentation complète est disponible ici.
Comme nous démarrons un container Docker, nous allons avoir besoin de définir un point de montage pour nos données. Ici, nous allons monter dans
/data le contenu à sauvegarder.
docker container run -d --name rclone \
-v /srv/rclone.conf:/config/rclone/rclone.conf:ro \
-v /srv/data/to/save/:/data/srv:ro \
-v /home:/data/local_homes:ro \
rclone/rclone \
copy /data NOM_DU_BUCKET:NOM_DU_BUCKET/
Cette commande Docker va monter le fichier de configuration précédemment créé, et vous permettre de sauvegarder le contenu de vos deux dossiers
/srv/data/to/save et /home dans votre bucket. Pensez à bien changer NOM_DU_BUCKET dans la commande ! Une fois de plus, c’est loin d’être
parfait (on préférera stocker les clefs et la configuration dans des endroits plus appropriés que directement sur disque par exemple), mais au moins,
notre POC fonctionne ! Une fois la commande exécutée, vos données devraient commencer a apparaître sur votre object storage. Maintenant que vous avez
compris le principe, à vous de jouer ! Configurez les dossiers que vous souhaitez, pointez vos backups de base de données à des endroits lus par votre
container, et laissez rclone gérer pour vous.
Dernière étape : Automatiser la sauvegarde
Automatiser
Pour cet exemple, nous allons rester très simple, et utiliser la crontab.
Ouvrez la crontab (crontab -e) d’un utilisateur pouvant exécuter des commandes Docker, et ajoutez la ligne suivante :
0 4 * * * docker start rclone
Voilà, votre backup se lancera tout les soirs à 4h du matin !
Et ça marche ?
J’utilise ce système en production depuis désormais 6 mois, et j’en suis ravi ! Grâce aux versions dans mon bucket, je peux conserver les versions de mes fichiers et revenir en arrière très simplement. Rclone offre de nombreuses fonctions très pratiques y compris pour effectuer une recovery depuis notre object storage. Je peux gérer mes fichiers unitairement, ce qui m’évite de télécharger un dump de 200Go à chaque fois que j’ai besoin d’une backup spécifique.
Petite nuance cependant, je vous ai présenté ici une version “simplifiée” de l’installation d’un tel système : Pour un réel déploiement, je vous encourage fortement à faire un déploiement plus propre que celui présenté (les secrets & configurations de Kubernetes ou Swarm sont vos amis).
Niveau coût, c’est également très abordable : Pour environ 200Go sauvegardé, je suis à moins de 50 centimes par mois. Autrement dit, c’est fiable, c’est simple, et c’est abordable ; tout ce qu’il nous faut pour une infra maison !
Surtout, comme rclone est compatible avec des dizaines de providers (y compris certains qui peuvent se self-hoster), je ne suis pas bloqué avec Scaleway : si je décide un jour de changer de provider, je pourrai le faire sans passer des journées à tout reconfigurer. Bien entendu, se pose la question de l’externalisation des sauvegardes et du risque que cela fait poser, mais ça, c’est pour une prochaine fois… 😉
Au secours, j’ai besoin de mes backups !
Vous avez besoin de fichiers de vos backups ? Plusieurs options s’offrent à vous !
Option 1 - Interface graphique
Le plus simple est de se connecter sur l’interface graphique de Scaleway, télécharger vos fichiers et de les renvoyer ensuite sur votre serveur.
Bon, c’est pas glamour… On peut mieux faire, peut-être ?
Option 2 - CLI !
Vous vous souvenez de notre container Docker plus haut ? Regardons la ligne de commande qui s’exécute dedans :
rclone copy /data NOM_DU_BUCKET:NOM_DU_BUCKET/
Ici, nous voyons que rclone va lancer une copie de l’ensemble du contenu de /data vers NOM_DU_BUCKET:NOM_DU_BUCKET/. Pour récupérer des fichiers
ou des dossiers, il suffit d’inverser les sens ! En générifiant un peu notre commande, au final, cela ressemble à ça :
rclone copy SOURCE DEST
Admettons par exemple que vous avez besoin de récupérer le contenu du dossier nextcloud du bucket, et le stocker temporairement dans /backup. La
commande sera alors :
rclone copy NOM_DU_BUCKET:NOM_DU_BUCKET/nextcloud /backup
Et c’est aussi simple que ça ! Si on souhaite directement le faire dans un container Docker, ce n’est guère plus compliqué :
docker container run -d --rm --name rclone-restore \
-v /srv/rclone.conf:/config/rclone/rclone.conf:ro \
-v /srv/restoration:/backup \
rclone/rclone \
copy NOM_DU_BUCKET:NOM_DU_BUCKET/nextcloud /backup
Ce container stockera ainsi l’ensemble des fichiers récupérés dans /srv/restoration, et se supprimera une fois l’exécution terminée.