Utiliser un RAG pour extraire et consolider des données d'un corpus documentaire ; c'est possible ?
This article is also available in English.
Si la gestion du patrimoine informatique et des données associées est un sujet fondamental des entreprises ayant un parc informatique depuis des décennies, il existe cependant un domaine proche mais malheureusement sous-exploité : celui du patrimoine documentaire d’une entreprise. Pourtant, ce domaine est probablement le plus transverse et le plus générique à la notion même d’une entreprise : chaque entreprise dispose de ses propres processus internes, de ses appels d’offres, des Curriculum Vitae de ses employés, de ses factures (tant en fournisseur que client), des appels d’offres auxquels elle répond, etc. Au travers de cet article, nous allons tenter de répondre aux questions suivantes :
- Pouvons-nous, d’une part, extraire un ensemble d’informations à partir d’un document, et les stocker de manière structurée ;
- Et, d’autre part, pouvons-nous requêter ces informations au travers d’un langage naturel, par exemple par le biais d’un Chatbot ?
Pour répondre à ces deux questions, nous avons menés plusieurs expériences visant à comparer les solutions actuellement disponibles “sur l’étagère”, mais également certaines implémentations proposées dans le monde de la recherche. Bien entendu, ces solutions s’appuient majoritairement sur des algorithmes de compréhension de texte issus de l’intelligence artificielle, afin de détecter, d’identifier et de cataloguer le contenu des documents de manière automatique et agnostique ; puisque le format des documents peut sensiblement varier au fil du temps.
Pour l’ensemble de ces tests, nous nous sommes basés sur un corpus documentaire composé de plusieurs CV de personnes inventées, ainsi que plusieurs appels d’offre reçus par la société datant d’il y a plus de deux ans. Chaque CV est composé d’un nom, d’un prénom, et d’un ensemble d’expériences professionnelles et de compétences techniques différentes. Notre objectif : réussir à constituer l’équipe de rêve pour ce projet répondre au projet de notre client. Cette expérimentation s’inscrit dans une démarche plus générale chez Zenika, visant a mieux connaître le contexte technique de nos clients afin de faciliter l’identification de leurs besoins, ainsi que les personnes les plus a même d’y répondre.
Étant donné que, dans un contexte d’usage réel, nous allons transmettre à cet outil des données potentiellement confidentielles ou critiques, nous souhaitons utiliser uniquement des solutions déployables on-premises, afin d’éviter toute fuite de données vers des opérateurs tiers.
Découverte d’un RAG
Un RAG (Retrieval-Augmented Generation) est une technique qui permet à une Intelligence Artificielle de récupérer le contenu d’un document afin d’en extraire et d’en synthétiser des informations. Dans le détail, le RAG va lire le document et en extraire son contenu, avant de le décomposer en morceaux (chunks). Cette étape est cruciale, car les LLM ne peuvent prendre qu’une certaine quantité d’information en contexte.
De manière induite, le RAG va donc gérer une autre étape importante : lorsqu’une requête va arriver à la LLM, le RAG va s’occuper de détecter les morceaux de documents potentiellement intéressants pour les donner en contexte au LLM.
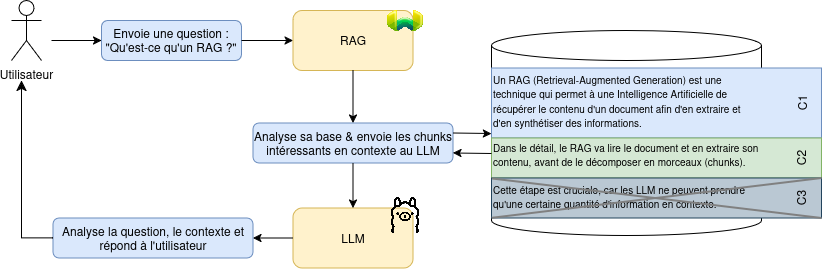
Figure 1 - Fonctionnement généraliste d’un RAG
Il existe plusieurs manières de découper un document en chunks. L’approche la plus basique consiste à effectuer un découpage sur le nombre de mots, ou de phrases. Par exemple, nous allons pouvoir configurer que chaque chunk sera composé de 10 phrases, ou de 150 mots. Le RAG va alors indexer le contenu de ce chunk, et le renverra en intégralité à la LLM lorsqu’il considérera que le chunk a une pertinence dans le contexte demandé par l' utilisateur.
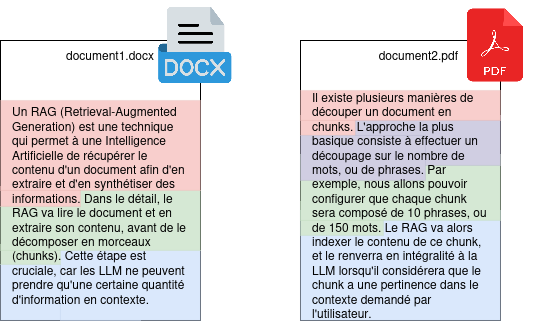
Figure 2 : Découpage d’un document en utilisant une séparation par phrase.
Dans l’exemple ci-dessus, nous avons deux documents, qui ont été découpé en 7 chunks (un chunk par phrase). Lorsque l’utilisateur enverra une requête à notre LLM, le RAG s’occupera de détecter les chunks potentiellement intéressants, et les injectera au LLM en tant que contexte afin de teinter la réponse avec les détails contenus dans nos documents.
Il est à noter que la configuration de la taille d’un chunk n’est pas anodine : des chunks plus gros permettront de mieux préserver le contexte global du document, mais en contrepartie, le RAG devra sélectionner moins de chunk à envoyer. Ce réglage est donc fortement dépendant de votre type de corpus documentaire.
Premiers essais
La première étape consistait à lister les solutions communautaires déjà disponibles pour notre usage. Plusieurs outils nous ont semblé prometteurs, que nous avons décidé d’expérimenter plus en détail :
- Kotaemon ;
- Verba ;
- AnythingLLM.
Ces outils ont tous pour point commun de permettre de construire simplement un RAG, utilisable par une interface graphique simple et intuitive. La majorité de nos tests ont porté sur Verba, puisque ce dernier permet un paramétrage beaucoup plus important sur la méthode de chunking, les modèles utilisés, etc.
Nous avons également expérimenté Dify, qui est un outil légèrement différent, puisqu’il s’agit ici davantage de concevoir des workflows complexes, permettant d’effectuer des actions successives (appels API, envoi de contexte à un LLM, etc). Étant donné qu’il est bien plus difficile à mettre en place et que notre besoin métier n’en a pas d’utilité réelle, nous avons écarté cette solution bien que très prometteuse.
Pour fonctionner, ces outils ont besoin de deux modèles de données (LLM, pour « Large Language Model »). Ces LLM vont être le cœur du système, puisque ce sont eux qui vont effectuer les tâches d’extraction de documents, d’analyse des demandes de l’utilisateur et de réconciliation de la donnée. Certains modèles sont disponibles en usage libre (notamment Llama), et d’autres sont propriétaires (comme GPT-4, conçu par OpenAI). Nous avons expérimenté les trois derniers modèles de Llama (3.1-8b, 3.2 et 3.3) afin de définir le modèle disposant du meilleur rapport « qualité de réponse / vitesse d’exécution ». Pour l’extraction du texte, nous avons utilisé nomic-embed-text, qui est un modèle spécialisé dans l’extraction d’informations de documents.
Afin de définir le meilleur modèle, nous avons, avec Verba, lancé plusieurs tests sur chacun des modèles à notre disposition :
- Un premier test consiste à demander à un modèle de nous résumer un document, par exemple un des CV de notre jeu de test. Sur cet exercice, nous constatons que nos trois modèles (llama3.1-8b, llama3.2 et llama3.3) retournent des résultats tout à fait similaire. A matériel d’exécution identique, les modèles llama3.1-8b et llama3.2 répondent en des temps sensiblement identiques, là où llama3.3 met plusieurs dizaines de secondes à générer une réponse complète ;
- Un second test consiste en l’envoi d’une présentation d’environ 60 diapositives présentant un plan d’action, et de demander au LLM de résumer le document fourni. Là, les résultats divergent entre llama3.1-8b et nos deux autres modèles : En effet, la version 3.1-8b a beaucoup de mal à traiter l’ensemble du contexte fourni. Ainsi, le LLM se contente de retourner une liste d’éléments génériques, décorélées du contenu réel de la présentation. Au contraire, les modèles 3.2 et 3.3 retournent des informations plus complètes et pertinentes.
Nous avons donc déterminé que le modèle le plus efficient pour notre cas d’usage serait llama3.2.
Ce test nous permet également de confirmer que le concept de RAG est valide et applicable lors de l’analyse d’un document unique : dans chacun de nos tests, nous avons pu vérifier que le LLM nous retourne des résultats cohérents et en phase avec le contenu du document envoyé. Cela signifie que le LLM accepte et utilise bien le contexte spécifique pour étendre sa base de connaissance originale.
Cependant, nos tests ont pris une tournure inattendue lorsque nous avons commencé à demander au LLM de consolider les données de plusieurs documents de manière simultanée.
Le chunking, ou l’enfer de la consistence
Comme vu précédemment, lorsque le RAG ingère un document, celui-ci va le décomposer en plusieurs morceaux, nommés chunks. Assez logiquement, chaque chunk va contenir un bout de la connaissance apportée par le document. Ce découpage est essentiel pour le travail d’un LLM : puisque le LLM n’accepte qu’un certain nombre de caractères en contexte, il est impossible de communiquer au LLM l’ensemble de notre base documentaire.
Lors d’une requête, le RAG va intercepter la demande avant qu’elle soit transmise au LLM, et vérifier dans sa base documentaire les chunks qui ont un intérêt dans le cadre de la question posée par l’utilisateur. Puis, le RAG va transmettre la question ainsi que les chunks jugés « intéressant » au LLM pour traitement. Ce fonctionnement implique cependant une limitation importante : Le LLM est incapable de connaître le contexte complet du document, puisque celui-ci ne reçoit qu’une partie de celui-ci.
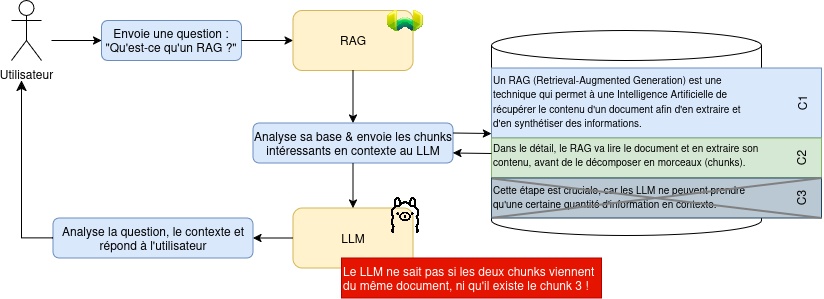
Figure 3 : Reprise de notre schéma global, avec la clarification sur les chunks.
L’absence de la connaissance complète du contexte engendre diverses limitations dans le fonctionnement d’un RAG, notamment le fait qu’aucune consistance de la donnée ne peut être garantie. Cette limite a malheureusement été très rapidement rencontrée durant nos tests ; et nous avons pu confirmer que le système de chunk est bien à l’origine du problème, en réduisant volontairement la taille des documents envoyés. Plus en détail, voici le protocole expérimental que nous avons utilisé pour confirmer ce problème :
Dans un premier temps, nous avons envoyé 5 CV complets au LLM ; chaque CV étant composé de 3 à 5 pages. Nous lui avons posé la question suivante : « En te basant sur l’ensemble des documents à ta disposition, donne moi les noms d’une équipe pouvant développer un projet en Golang, utilisant Terraform et GitLab, et une base de donnée PostgreSQL ». A chaque fois, le LLM nous a indiqué être incapable de fournir une réponse à cette question, car aucune personne ne se trouve dans sa base documentaire. Cette absence de reponse est due au découpage des documents, puisque le RAG identifie des morceaux de document ne contenant que les noms de technologie, mais pas les noms et prénoms des personnes. Le LLM ne comprend alors pas la demande qui lui est fournie, car il n’est pas capable de reconstruire le contexte complet des documents qui lui sont transmis par le RAG.
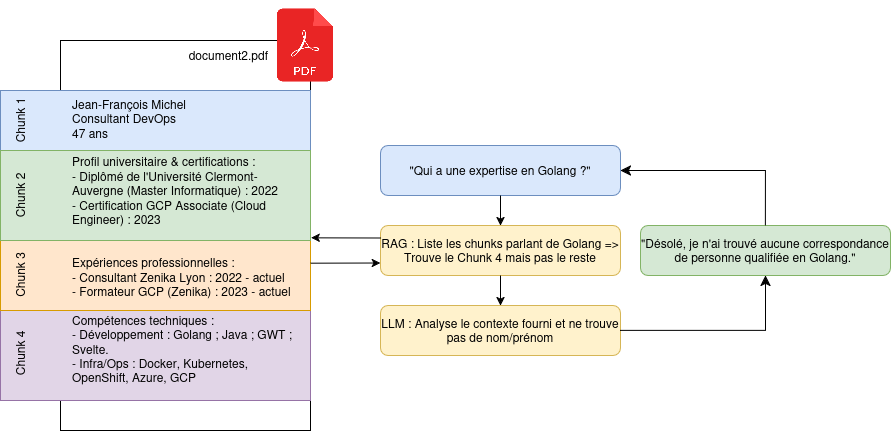
Figure 4 : Démonstration du problème de chunking avec l’exemple d’un CV.
Ensuite, nous avons supprimé les 5 documents, et avons renvoyé le résumé de chaque CV, composé à chaque fois du nom, prénom, poste et d’une courte biographie de chaque personne. Dans le résumé, nous avons pris soin de glisser les technologies voulues pour le projet. Lorsque nous avons soumis le même prompt au LLM, celui-ci a été capable de nous répondre une équipe-type de trois personnes cohérente, et composée des personnes présentes dans les CV. Cette solution est possible car le document est suffisamment petit pour tenir dans un seul chunk, et le RAG va donc communiquer le document entier au LLM, qui va donc avoir une connaissance complète du contexte. Cette solution fonctionne, mais présente des limitations évidentes, puisque le contexte pouvant être envoyé au LLM est limité en taille. Cette solution n’est donc pas viable sur le long terme, ou avec de longs documents.
En désactivant totalement le chunking, le résultat n’est pas plus probant : le contexte dépasse alors les limites tolérées par le LLM, et celui-ci ignore alors tout simplement les documents fournis en contexte, ce qui aboutit à une réponse invalide.
Nous avons, au cours de nos tests, expérimenté une autre situation déroutante : En prenant un prompt et un jeu de documents fonctionnel, et en reposant plusieurs fois le même prompt, notre modèle (llama3.2 ici) se met à fortement dériver dans ses réponses. Si la première itération retourne un résultat totalement cohérent et valable, la deuxième, troisième et quatrième itération retournent des résultats de plus en plus aberrants (des confusions dans les capacités des personnes vis à vis de leurs CV, l’invention de nouveaux noms/prénoms, etc). La conservation du contexte semble donc être une limitation à la cohérence du jeu de donnée, même sans prompt dédié à abaisser la qualité de réponse.
Nous faisons donc face ici à une double limitation :
- Nous ne pouvons pas désactiver le chunking sans détruire l’intérêt du RAG ;
- Nous ne pouvons pas conserver le chunking car le LLM génère des réponses improbables (également nommées hallucinations).
Le chunking sémantique & par axiomes
En parcourant divers documents de recherche, nous sommes tombés sur deux solutions potentielles à notre problème de contextualisation.
Chunking sémantique
L’objectif du chunking sémantique est assez simple : Au lieu de découper des documents à partir d’un nombre arbitraires de mots ou de phrases, nous allons utiliser un moteur de langage naturel afin de comprendre le contenu du document, et le découper par regroupement sémantique. Ce fonctionnement va aboutir en un ensemble de chunks de tailles différentes, mais contenant chacun un ensemble d’informations fortement liées entre elles.
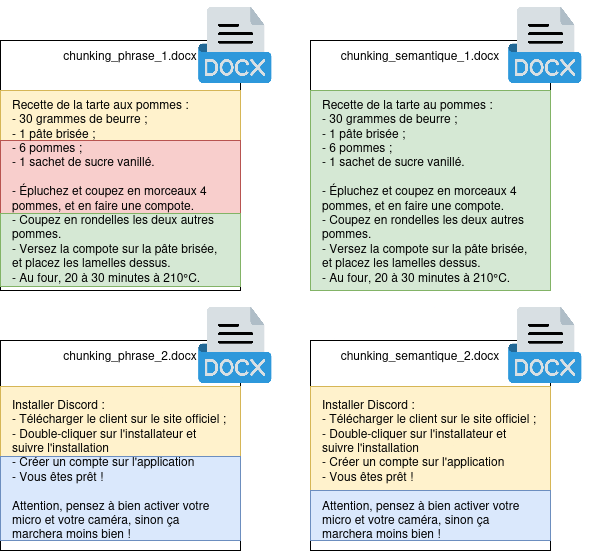
Figure 5 : Découpage par phrase vs. sémantique. Le document est découpé de manière cohérente afin de préserver un contexte propre à chaque chunk.
De cette manière, nous réduisons le risque d’hallucination en donnant à notre modèle des informations cohérentes et déjà qualifiées par un outil auparavant. Cependant, cette approche présente diverses limitations. Premièrement, cette méthode est encore hautement expérimentale, et les implémentations sont rares, ce qui oblige de développer soi-même ce genre de fonctionnalités. Pour cela, certaines librairies, comme spaCy, peuvent se révéler très utiles. Secondement, ce fonctionnement demande davantage d’énergie et de temps de calcul, puisque le document doit subir une étape d’analyse avant d’être découpé et stocké ; et ce coût n’est pas négligeable sur de larges corpus documentaires. Enfin, cette méthode repose sur de l’analyse linguistique : des documents avec des tournures de phrases alambiquées ou dans des langues non-supportées par notre analyseur linguistique pourraient retourner énormément de mauvais résultats, et polluer le reste du corpus documentaire.
Le fonctionnement par axiome
Un autre fonctionnement proposé dans la recherche est de stocker des axiomes à la place du document entier. L’objectif ici est de décomposer l’information en un ensemble de phrases minimales et auto-suffisantes.
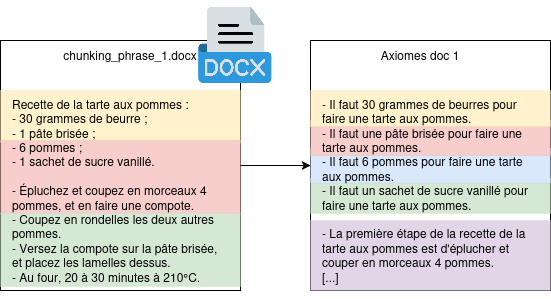
Figure 6 : Découpage par phrase vs. par axiome. Chaque axiome devient un chunk qui peut être communiqué en contexte au LLM.
Pour qu’un axiome soit considéré comme valide, il doit être atomique (une seule vérité est exprimé dans l’axiome), auto-suffisant (son contexte est totalement défini en son sein), et ne doit pas pouvoir être séparé en plusieurs sous-axiomes. Cette approche permet de sensiblement améliorer la qualité de réponse du LLM sur de larges modèles de données (les chercheurs notent une amélioration relative de 25%, soit une amélioration absolue de 11% de précision du résultat), mais augmente le temps d’ingestion des documents. Par ailleurs, se pose le problème de la génération de ces axiomes : Cette démarche nécessite l’appel à un LLM pour prendre les informations du document, et en extraire les informations. De la même manière que sur le chunking sémantique, des problèmes lié au langage naturel peuvent survenir, et sont même plus nombreux : dans un fonctionnement par axiome, nous cherchons à éliminer tout les pronoms nominaux.
Par exemple, dans le document « Florian est un développeur, qui aime également les pommes. Il s’intéresse également à l’aéronautique » ; nous nous attendons à avoir trois axiomes :
- « Florian est un développeur » ;
- « Il aime également les pommes » ;
- « Il aime l’aéronautique ».
Ces axiomes sont valables et facilement compréhensibles pour un être humain ; mais ne sont pas suffisants pour un LLM : puisque chaque axiome peut être envoyé individuellement à la LLM, le pronom « Il » devient indéfini ; il est alors impossible de savoir qui est réellement concerné par cet axiome. Les axiomes corrigés sont donc :
- « Florian est un développeur » ;
- « Florian aime également les pommes » ;
- « Florian aime l’aéronautique ».
Cette opération, triviale pour un être humain, est cependant très complexe pour un LLM, puisqu’elle requiert une connaissance fine de la langue française et de ses spécificités. Dans nos tentatives, y compris avec des modèles propriétaires (comme GPT-4), nous avons eu des résultats assez intrigants (comme, par exemple, « Les pommes aiment l’aéronautique »). Cette approche nécessite donc un traitement humain préalable afin de vérifier la validité des axiomes, et limite de fait son usage à grande échelle.
Conclusion
L’approche RAG présente une solution intéressante dans les tâches demandant de résumer un document et d’en exploiter son contenu dans une conversation en langage naturel avec un LLM. Toutefois, le fonctionnement de la contextualisation d’un LLM impose de fortes contraintes difficilement surmontables, car les contournements imposent une analyse sémantique complète du document, pouvant être source d’erreur et d’approximation nuisant fortement à la qualité des contextes fournis aux LLM.
Si nos tests ont pu mettre en évidence un réel cas d’usage dans le cadre d’un mono-document, nos diverses tentatives afin d’obtenir un résumé ou une consolidation de plusieurs documents n’ont jamais abouti à un résultat convenable pour un usage intensif ou systématisé : les sources d’erreur restent trop fréquentes et la qualité du contenu s’en fait ressentir.
D’autres solutions alternatives semblent émerger, notamment le concept de graphe de connaissance. Cette approche, notamment explorée par GraphRAG, consiste à créer des graphes pondérés contenant les données d’un document afin de pouvoir requêter ce graphe, et d’obtenir ainsi des résultats compréhensibles et reproductibles ; réduisant ainsi le risque d’hallucinations des LLM. Cependant, cette approche nécessite tout de même une forte analyse sémantique du texte fourni en contexte; et engendre donc les mêmes problématiques que celles évoquées plus tôt sur le chunking sémantique. Dans cette approche, nous nous rapprochons fortement de solutions déjà existantes et éprouvées (RDF, Web Sémantique), en utilisant la puissance de l’IA pour identifier et classifier les informations d’un document.
Sources
- Dense X Retrieval: What Retrieval Granularity Should We Use? [arXiv:2312.06648]
- From Single to Multi: How LLMs Hallucinate in Multi-Document Summarization [arXiv:2410.13961v1]
- MDCure: A Scalable Pipeline for Multi-Document Instruction-Following [arXiv:2410.23463]
- Generating Knowledge Graphs from Large Language Models: A Comparative Study of GPT-4, LLaMA 2, and BERT [arXiv:2412.07412]
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization [arXiv:2404.16130]
Cet article est un repost du billet de blog écrit pour Zenika.