Docker Swarm, c'est quoi (et comment ça marche) ?
This article is also available in English.
Dans la vie, nous avons tous des combats que nous savons perdus d’avance mais qui nous tiennent à coeur. Une sorte d’obsession, un truc irrationnel que personne ne comprend réellement, hormis vous. Aujourd’hui, laissez-moi vous présenter plus en détail une de mes obsessions : Docker Swarm.
En deux mots avant de commencer, Docker Swarm, c’est un orchestrateur de containers qui a la particularité de faire du clustering : vous installez Docker Swarm sur plusieurs serveurs (ou machines virtuelles), et Docker Swarm va automatiquement répartir vos containers sur ces machines. Docker Swarm existe depuis plusieurs années maintenant, et est un produit considéré comme étant mature et utilisable sans gros bémol en production. C’est une alternative à un autre outil bien plus connu, hype et utilisé : Kubernetes.
La genèse de Docker Swarm
Tout commence en 2014 (il y a 10 ans de cela). A l’époque, Docker est un produit tout juste émergeant, et certains utilisateurs commencent à avoir besoin de haute disponibilité sur leurs déploiements. La stratégie en ce temps est assez basique : on déploie soi-même des containers sur plusieurs machines, et on gère chaque container indépendemment des autres. C’est lourd à gérer, c’est compliqué à maintenir, les mises à jour sont casse-gueule… Bref, personne n’aime ça. C’est à ce moment-là que plusieurs projets vont voir le jour pour tenter de simplifier tout cela, et notamment Docker Swarm, et Kubernetes.
Ces outils sont bâtis comme étant des “wrappers” autour de Docker : au lieu de créer des containers directement sur Docker, vous allez créer un “service” sur Docker Swarm ou Kubernetes, qui va alors s’occuper de le déployer, le maintenir à jour, le faire communiquer via des réseaux virtuels, et ainsi de suite. Plus tard, Kubernetes supprimera l’adhérence obligatoire à Docker en permettant d’utiliser directement containerd en isolateur, mais c’est une autre histoire.
Et à l’époque, Docker Swarm, c’est un peu (doux euphémisme) assez pourri : Ça fonctionne mal, notamment la partie réseau, les mises à jour de services sont complexes, etc. Kubernetes prend un énorme ascendant, notamment poussé par les ingénieurs de Google qui sont aux manettes du projet et qui proposent des offres “Kube as a Service” dans Google Cloud Platform avec la subtilité d’un troupeau d’éléphant visitant le musée de la porcelaine de Limoges.
Et Docker Swarm va ainsi vivre, de 2014 à 2018, une lente et longue agonie, rongé par les bugs techniques, dépassé fonctionnellement et techniquement par Kubernetes, abandonné par la société Docker qui ne voit aucun avenir en lui… Jusqu’à début 2019, où Docker va annoncer l’arrivée Docker Swarm.
Docker Swarm != Docker Swarm
Si vous avez correctement lu ma ligne précédente, vous vous êtes sûrement dit que j’avais écrit n’importe quoi sans me relire. Mais non, je maintiens bien ma phrase d’avant ; car Docker Swarm n’est pas Docker Swarm.
Comme dit précédemment, la première version de Docker Swarm était un wrapper autour de Docker. En 2018, Docker abandonne le projet face à l’échec total de la tentative de concurrencer Kubernetes et du profond désintérêt de la communauté. Cette version est désormais appelée “Docker Swarm Classic”, et est à elle seule responsable de la grande majorité des biais et défauts souvent reprochés à Swarm.
Puis, en 2019, Docker (notamment avec le rachat des activités Enterprise par Mirantis) annonce le retour de Docker Swarm, mais ce coup-ci, Swarm est directement bâti dans Docker : lorsque vous installez Docker, Swarm est fourni dans le binaire, prêt à être utilisé. Cela signifie que Swarm peut accèder à toutes les APIs de Docker (et même plus), et que la compatibilité entre Docker Engine et Docker Swarm est toujours garantie. Par ailleurs, cette uniformisation rend l’apprentissage de Swarm très simple : si vous utilisz déjà Docker, vous connaissez déjà 90% de Swarm ! Et c’est à partir de là que Docker Swarm va devenir un produit réellement intéressant.
Et c’est également là que nous quittons l’histoire de Swarm pour commencer à parler des considérations techniques ! Comme vous l’avez compris, nous allons parler dans cet article exclusivement de Docker Swarm (de 2019 à aujourd’hui), et non du mode classique. Aller, c’est parti.
Mise en place d’un lab
Pour l’ensemble de ce billet, nous allons considérer que nous avons trois machines virtuelles, qui peuvent parler entre elles. Si vous avez un firewall physique ou virtuel, vous devez vous assurer que les ports suivants sont ouverts entre vos trois machines virtuelles :
7946/tcp&7946/udppour la découverte des réseaux overlay ;4789/udppour les réseaux Docker overlay ;2377/tcppour la communication entre les managers ;- Et le protocole
IP 50(IPSec) pour les réseaux chiffrés.
Si vous n’avez pas de machines virtuelles ou de matériel à la maison, je vous recommande fortement les instance d2-2 chez OVHCloud, ou des DEV1-S chez Scaleway (environ 1 centime par heure), ce qui vous permet d’avoir à très faible coût un environnement de test fonctionnel.
Vous pouvez déployer n’importe quelle distribution Linux sur ces instances, tant qu’il est possible d’installer Docker (Community Edition) dessus. Pour mes tests, j’ai l’habitude d’utiliser Alpine Linux, puisque l’installation est très facile (apk add docker) et que l’image est très légère, ce qui optimise grandement l’utilisation des ressources.
Concepts techniques
Les nodes
Comme vu plus haut, Docker Swarm est un outil de mise en cluster de serveurs Docker. Pour cela, Docker Swarm se repose de manière intensive sur le fonctionnement de Docker Engine pour en étendre les fonctionnalités et les faire fonctionner entre plusieurs machines partageant un même réseau physique.
Dans Docker Swarm, une machine va être nommée node. Un cluster peut contenir autant de nodes que vous le souhaitez. Ces nodes se décomposent en deux catégories : les nodes manager et les nodes worker.
Les managers
Un noeud manager est responsable du cluster : il permet à l’utilisateur de taper les commandes permettant de gérer l’état du cluster et des services déployés dessus. Il gère l’ordonnancement des services, vérifie leurs état de santé, redémarre les services au besoin, etc.
Chaque cluster dispose (normalement) de plusieurs manager. Afin de synchroniser tout le monde, Docker Swarm utilise un algorithme de consensus (nommé Raft), qui permet de faire en sorte que tous les managers naviguent dans le même sens. Pour cela, le cluster élit un Leader, garant de l’état du cluster. Ce cluster est élu par un système de vote, le noeud ayant la majorité des votes remporte l’élection. Si le leader vient à tomber hors-ligne, le cluster organise une nouvelle élection. Pour cette raison, il est recommandé de toujours avoir un nombre impair de noeuds manager : sans cela, vous risquez de vous retrouver dans un cluster où personne n’arrive à avoir 50% des votes !
Pour les utilisateurs du cluster, la notion de Leader est un concept invisible : n’importe quel noeud manager peut accepter les commandes et les appliquer.
Enfin, les managers peuvent également exécuter les services (= containers pour l’instant, on va en reparler) définis par l’utilisateur, et c’est même le comportement par défaut. Vous pouvez donc avoir un cluster composé à 100% de managers.
Les workers
Un worker est un type de node avec moins de privilèges dans le cluster : il se contente d’exécuter les services. Un worker ne peut pas recevoir de commandes venant d’un utilisateur, ne participe pas à l’élection du leader, et ainsi de suite.
Les workers sont recommandés uniquement pour des besoins très spécifiques (déploiements de services qui doivent rester isolés ou qui ne doivent pas être impactés par le control plane, etc). Dans notre lab, nous n’utiliserons pas de workers.
Les services
Dans Docker Swarm, nous ne déployons pas des containers, mais des services. Un service est défini par une image Docker que nous allons lancer (comme un container), et qui va disposer d’options supplémentaires par rapport à un container classique, notamment pour gérer la haute-disponibilité, et les mises à jour.
Un service peut être mis à jour, et chaque propriété d’un service peut être changé sans avoir besoin de le détruire et le recréer (variable d’environnement, version d’image, etc).
Ainsi, en supplément des ports, des volumes, des variables d’environnement, nous allons pouvoir définir :
- Du healthcheck : En complément du healthcheck d’un container Docker, Swarm va automatiquement redémarrer les services malades ;
- Des réplications : Nous pouvons définir le nombre de copies du service qui doivent fonctionner en même temps, soit en indiquant un nombre de répliques, soit en forçant Swarm à lancer une instance du service sur chaque noeud ;
- Des politiques de mise à jour et de rollback : Nous pouvons définir à Docker Swarm comment mettre à jour un service (combien de containers supprimer/recréer en parallèle, avec quel délai entre chaque opération, etc), ainsi que la politique de rollback en cas d’échec de mise à jour (revenir en arrière, mettre en pause le déploiement, etc).
Une fois toutes ces possibilités prise en compte, voici ce à quoi peut ressembler une déclaration de service :
docker service create \
--name demo-website \
--update-delay 10s \
--update-parallelism 1 \
--replicas=2 \
--publish published=8000,target=80,mode=ingress \
--update-failure-action rollback \
--health-cmd 'curl http://localhost/index.html --fail' \
--health-interval 2s \
--health-retries 4 \
--health-start-interval 10s \
httpd:latest
Ne vous inquiétez pas, nous allons revoir tout cela ensemble ensuite.
Le réseau
Dans Docker Swarm, un réseau créé sur une machine est automatiquement propagé aux autres machines. Ainsi, un docker network create --scope swarm bonjour va générer un réseau Docker utilisable sur les trois machines de votre cluster (et, si vous ajoutez des machines, ces nouvelles machines prendront automatiquement le réseau). Les services qui utilisent ce réseau vont pouvoir communiquer entre eux et entre les noeuds physiques de votre cluster de manière totalement transparente.
Cerise sur le gâteau, si votre cluster doit communiquer sur Internet pour s’échanger des informations (exemple : vous n’avez qu’une carte réseau qui sort sur Internet sur vos machines), vous pouvez chiffrer le réseau nativement via IPSec : docker network create --scope swarm --opt encrypted=true bonjour.
Pour le reste : tout fonctionne exactement comme sur un noeud Docker classique ! En complément des réseaux de Docker, Swarm apporte tout de même deux fonctionnalités très pratiques :
Le DNS intégré
Comme sur un réseau “classique” Docker, Swarm apporte du DNS intégré dans les réseaux virtuels Docker. Ainsi, tasks.NOM_SERVICE renverra l’IP de l’ensemble des containers actifs d’un service spécifié.
Encore plus pratique, cet enregistrement DNS n’affiche que les containers qui sont healthy ! Ainsi, un container en cours de démarrage ou malade ne sera pas exposé. Ce fonctionnement vous permet de facilement interconnecter des services, en utilisant un enregistrement DNS pour faire communiquer ces services entre eux.
Le service-mesh
Lorsque vous publiez un port sur un service, il est possible de publier ce port de deux façons différentes : overlay et host.
En mode overlay, Docker Swarm va automatiquement prendre les requêtes arrivant sur n’importe quelle machine du cluster, et les rediriger de manière invisble vers un noeud du cluster qui expose réellement ce service. Par exemple, un serveur HTTP qui tourne en une seule réplique sur le cluster pourra en réalité être joint sur les trois adresses IP du cluster !
En mode host, Docker Swarm ne forward pas les paquets d’un noeud à l’autre : le service est exposé sur les machines sur lesquelle il tourne actuellement.
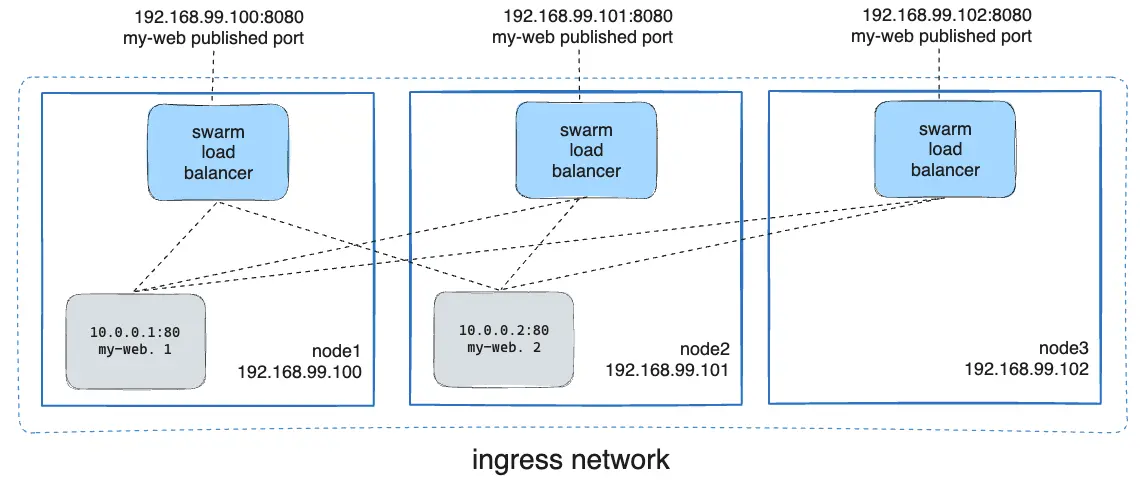
Ici, ce schéma résume le fonctionnement sur Service Mesh de Docker Swarm, si vous exposez un port en mode ingress : toutes les machines peuvent répondre à une requête sur ce port, car Swarm redirige les appels de manière transparente vers un container quelque part sur le cluster.
Le stockage
Cette partie va être très rapide : Docker Swarm ne propose aucun moyen de stocker des données entre chaque noeuds. Si vous avez besoin de partager des données entre les noeuds (par exemple pour une base de données partagées, ou un serveur de fichier), vous devrez déployer par vous même un serveur de fichier (Ceph, Gluster, ou autre).
A noter toutefois l’arrivée prochaine de CSI au sein de Swarm.
Toutefois, Docker Swarm inclus une gestion de configurations et de secrets grâce à docker secret et docker config. Ces deux commandes permettent de créer des secrets et des configurations sous la forme de fichiers, qui vont pouvoir être chargés dans des services. Ces secrets et configurations sont en lecture seule, et ne peuvent pas être mis à jour : si vous devez apporter une modification, il vous faut créer une nouvelle version du secret/configuration, et mettre à jour le service avec.
Nous venons de faire le tour des concepts techniques de Docker Swarm. Vous êtes toujours là ? Parfait, passons à la pratique maintenant !
Hands-on sur Swarm !
Déployer notre cluster
Premièrement, nous allons déployer notre cluster Swarm. Pour cette expérimentation, j’utilise trois machines virtuelles (2vCPU, 2Go de RAM, 10Go de disque) sur un OpenStack privé. J’installe les machines sous Alpine Linux 3.20, mais libre à vous d’installer un autre OS : la seule condition pour que cela fonctionne, c’est que Docker soit disponible sur cette distribution. N’importe quelle distribution Debian-based ou RHEL-based fera l’affaire. Sur ces trois machines, j’installe Docker exactement de la même manière que pour un mode standalone. Pour votre distribution, consultez le guide d’installation officiel.
Si vous avez un firewall logique et/ou physique, pensez à bien ouvrir les ports nécessaires (voir Mise en place d’un lab).
Maintenant que notre cluster est prêt (chaque machine répond “correctement” à un docker ps -a), nous allons mettre en place notre cluster Swarm. Sur la première machine, tapez la commande docker swarm init. Docker va vous indiquer qu’un noeud Swarm a bien été créé, et que vous pouvez commencer à ajouter du monde au cluster. Attention, le token indiqué par Swarm au retour de cette commande est un token pour faire rejoindre des workers, mais nous, nous voulons des managers. Tapons la commande docker swarm join-token manager pour obtenir la commande permettant d’ajouter des noeuds manager au cluster ; et copiez cette commande sur vos deux autres machines virtuelles.
Félicitations, vous venez de monter un cluster Swarm. 🎉
Pour vous en assurer, vous pouvez taper la commande docker node ls. La commande devrait vous afficher quelque chose de similaire à ceci :
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
bc91l1i0kx * swarm-1 Ready Active Reachable 26.1.5
5t4xm4b3h4 swarm-2 Ready Active Reachable 26.1.5
bea6az2b4w swarm-3 Ready Active Leader 26.1.5
Le plus important ici, c’est que toutes les instances soient bien en status Ready, et que toutes nos machines soit en manager status Reachable ou Leader : cela signifie que tout le monde arrive à communiquer ensemble.
Gérer les nodes
La commande docker node ls permet d’obtenir des informations intéressantes sur notre cluster :
- L’identifiant de chaque machine ;
- Le nom de chaque machine ;
- Son statut (
ReadyouUnreachable) ; - Son “availability” (
ActiveouDrain) ; - Son statut au sein du cluster (
Leadersi maître du cluster,Reachablesi ce noeud peut devenir manager, et vide si le noeud est un worker) ; - Et enfin, la version de Docker Engine présent sur cette machine.
Vous pouvez ajouter autant de machines virtuelles que vous le souhaitez, il vous suffira de récupérer un nouveau token avec la commande docker swarm join-token manager|worker et de recommencer l’opération que nous venons d’effectuer. Un noeud ne peut appartenir qu’à un cluster Swarm à la fois.
Il est également possible de promouvoir ou démettre de ses fonctions un noeud : docker node promote <id> permet de transformer un worker en manager, et docker node demote <id> permet de faire le chemin inverse. Je trouve personnellement que l’utilité de cette feature est assez limitée, mais qu’importe.
Nous reviendrons un peu plus tard sur les noeuds et notamment sur le labelling et cette notion de “Availability”. En attendant, notre cluster fonctionne, alors créeons un service !
Notre premier service
Un service, dans Swarm, c’est le nerf de la guerre, puisqu’il s’agit des containers que vous allez déployer sur votre cluster. Techniquement, un service est une définition de container Docker, avec quelques ajouts notamment sur la réplication et la gestion des mises à jour. Swarm prend en paramètre des services, et va générer un ensemble de containers sur votre infrastructure pour que le service se comporte comme vous l’avez décrit.
Pour les habitués du monde de Kubernetes, une différence majeure ici par rapport aux pods est qu’un service gère une seule définition de container : par exemple, un pod “monitoring” sur Kubernetes contenant votre Grafana/Prometheus devra ici être représenté sous la forme de deux services ; l’un dédié à Prometheus et l’autre à Grafana.
Un service est toujours déployé sur l’ensemble du cluster : on peut ajouter des règles d’affinité pour définir où vont se générer les containers, mais, par défaut, n’importe quel même du cluster peut être choisi pour faire tourner un container de votre service.
Sur chaque service, nous allons pouvoir définir le nombre de réplicas :
- Si le mode de réplication est
global, un container du service sera démarré sur chaque instance physique ; - Si le monde de réplication est
replicated, l’utilisateur contrôle le nombre de containers du même service actifs sur le cluster : par exemple, un réplica 2 sur notre servicegrafanapermettra de démarrer deux containers de ce service là sur nos trois machines physiques.
Pour récapituler toutes ces informations, voici un petit schéma de démonstration :
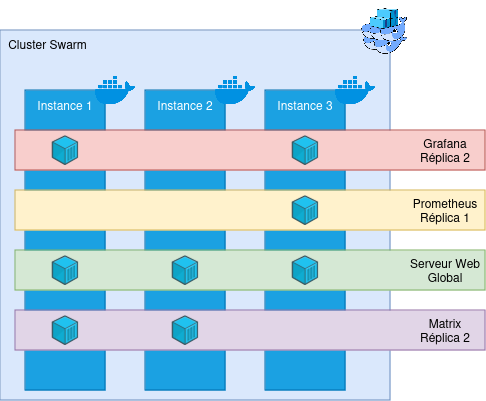
Ici, nous avons un cluster de trois machines, et 4 services sont déployés dessus : Grafana, Prometheus, un serveur Web, et un serveur Matrix, avec chacun des réplicas différentes. Docker Swarm va alors contacter les Docker Engine sur les machines physiques, et démarrer des containers sur ces machines physiques. En supplément, Swarm va rajouter un peu d’interconnectivité entre les machines (voir la partie Le réseau pour un petit rappel). Même si l’instance 2 n’a pas de container Grafana déployé, il est au courant que ce service existe.
Créons notre premier service, tout simple :
docker service create \
--name demo-website \
--mode replicated \
--replicas 2 \
--publish published=8000,target=80,mode=ingress \
httpd:latest
Ici, nous allons créer un service tout simple, nommé demo-website, qui va être répliqué sur deux noeuds de notre cluster. Ce service va également exposer le port 8000 vers le port 80 en mode ingress (ce qui signifie que Docker va effectuer du service mesh) ; et se base sur l’image httpd:latest.
Lancez cette commande sur votre lab, et, si tout va bien, vous devriez pouvoir accèder à ce service depuis n’importe quel noeud du cluster ! Félicitations, vous venez de créer votre premier service Docker Swarm.
Vous constaterez ici que nous avons utilisé une image Docker : cela signifie que n’importe quel image Docker est compatible nativement avec Swarm. Vous n’avez pour ainsi dire aucune action à faire pour passer d’un Docker à un Docker Swarm (sauf si votre application est stateful, bien entendu).
Depuis n’importe quel machine du cluster, vous pouvez lancer les commandes permettant de contrôler les services :
docker service lsvous permet de voir l’ensemble des services actuellement déployés sur le cluster, ainsi qu’un récapitulatif sommaire de l’état du service (nombre de réplicas, image utilisée) ;docker service ps <nom_ou_id_de_service>vous permet de voir l’emplacement des containers déployés pour votre service, et leur état (s’ils sont up/down, depuis combien de temps, etc). Il est à noter qu’un container qui meurt sera automatiquement détruit et recréé ailleurs par Swarm , ce qui en fait un système assez astreinte-friendly.docker service logs <nom_ou_id_de_service>vous permet de voir les logs de l’ensemble du service ; c’est à dire de tout les containers exécutant actuellement le service, mais également de tout les anciens containers de ce service.docker service inspect <nom_ou_id_de_service>vous permet de voir l’ensemble de la configuration d’un service : sa date de création, de mise à jour, les variables d’environnements communiquées, etc.docker service rm <nom_ou_id_de_service>qui vous permet de supprimer un service (😢).- Et
docker service update [...] <nom_ou_id_de_service>, qui permet de mettre à jour un service (mais on en reparle après !).
Lancez ces quelques commandes, et familiarisez vous avec la CLI de Docker Swarm.
Nous pouvons également modifier le nombre de réplicas d’un service (uniquement en mode replicated) : Tapez la commande docker service scale demo-website=3, et regardez avec docker service ps : nous venons de créer une nouvelle réplica de notre container ! Il est ainsi très simple de scale-up/down nos services.
Une fois que vous vous sentez prêt, nous allons passer à des créations de service un peu plus complexes… (et supprimez le service que nous venons de créer).
Le healthcheck
Si vous mettez du healthcheck sur votre service, Docker Swarm va automatiquement monitorer l’état de chaque container, et redémarrer les containers malades ! Ce système vous permet, lorsqu’il est bien utilisé, de drastiquement réduire les temps d’indisponibilité et vos appels nocturnes. 👀
Le healthcheck de Swarm se base totalement sur celui de Docker ; aussi les arguments à fournir sont identiques à ceux de la création d’un container :
docker service create \
--name demo-website \
--mode replicated \
--replicas 2 \
--publish published=8000,target=80,mode=ingress \
--health-cmd 'curl http://localhost/index.html --fail' \
--health-interval 2s \
--health-retries 4 \
--health-start-interval 10s \
httpd:latest
Ici, nous ajoutons les quelques options de healthcheck à notre description de service : Toutes les deux secondes, nous allons contacter http://localhost/index.html depuis l’intérieur de chaque container. Si le test échoue 4 fois consécutive, alors Swarm va détruire le container et en recréer un. Enfin, nous ajoutons un petit délai au moment de la création du container avec --health-start-interval pour laisser le temps au container de démarrer avant de tester son état.
Lancez la commande, et regardez le fonctionnement du healthcheck. Vous pouvez également détruire et recréer le service avec une commande de check volontairement erronée pour voir Swarm à l’oeuvre.
Il est à noter que Swarm n’attend pas passivement les informations du Docker Engine ; il les supervise par lui-même : si vous vous amusez à supprimer un container d’un service, Swarm va automatiquement le détecter et en recréer un nouveau dans la foulée (vous pouvez vous amuser à docker rm -f $(docker ps -aq) sur un de vos noeuds pour en avoir la preuve).
Supprimez votre service pour la dernière fois, car il est désormais temps de voir comment mettre à jour un service !
Mettre à jour notre service
Sur Docker, vous avez l’habitude de devoir supprimer et recréer votre container lorsque vous avez besoin de modifier son comportement, son image, ou autre. Sur Docker Swarm, une commande est à notre disposition pour cela : docker service update. Cette commande est extrêmement utile, puisqu’elle va nous permettre d’effectuer des opérations sur nos services (mettre à jour une version, une variable d’environnement, une configuration ou autre) sans interrompre notre service !
Dans un premier temps, nous allons recréer notre service, mais cette fois-ci avec quelques arguments en plus : des configurations de mise à jour et de rollback :
docker service create \
--name demo-website \
--mode replicated \
--replicas 2 \
--publish published=8000,target=80,mode=ingress \
--health-cmd 'curl http://localhost/index.html --fail' \
--health-interval 2s \
--health-retries 4 \
--health-start-interval 10s \
--update-delay 10s \
--update-parallelism 1 \
--update-failure-action rollback
httpd:latest
Ici nous définissons à Docker Swarm qu’il va pouvoir mettre à jour un container à la fois, et respecter un délai de 10 secondes entre chaque mise à jour. En cas d’échec, on demande à Swarm d’effectuer une annulation de la mise à jour du service. La référence complète est disponible sur la documentation.
Une mise à jour de service permet de modifier absolument n’importe quel élément de votre service : configuration, environnement, commande communiquée à l’entrypoint, l’image Docker utilisée, les ports publiés, etc… La référence complète est disponible sur la documentation.
Dans notre premier exemple, nous allons tenter de mettre à jour notre service pour remplacer notre serveur httpd par un serveur MariaDB : il est donc fort peu probable que cela fonctionne, puisqu’il va manquer énormément de détails au service pour démarrer (à commencer par un mot de passe administrateur), et le healthcheck ne peut de toute façon plus fonctionner. Regardons comment Swarm se comporte : docker service update --image mariadb:latest demo-website.
Rapidement, vous devriez avoir une “task failure detected” sur votre écran, et Swarm va automatiquement retourner à l’ancienne définition de l’image (et donc au serveur Web classique). De plus, votre service ne s’est pas interrompu une seule seconde du point de vue de vos utilisateurs !
Maintenant, mettons à jour notre service pour lui faire démarrer un serveur PHP : docker service update --image php:latest demo-website. Ce coup-ci, le healthcheck devrait passer, et vous devriez voir votre service se mettre à jour petit à petit, jusqu’à avoir un service converged. Félicitations, vous venez de mettre à jour votre premier service ! C’était pas compliqué, si ? 😁 Cette logique s’applique à l’ensemble des opérations de mise à jour, et se base sur le même principe : Swarm détruit un premier container pour construire la nouvelle version, attend que le container soit stable, puis en supprime un second, et ainsi de suite. Si vous avez compris la logique de mise à jour avec une image, vous avez tout compris !
Étant donné que chaque appel à docker service update entraîne la suppression et la re-création des containers du service, on fera en sorte à grouper les opérations de mise à jour plutôt que de faire une commande par paramètre à mettre à jour.
Enfin, sachez que vous pouvez utiliser docker service update --force <nom_ou_id_du_service>. L’argument --force va obliger Docker Swarm à détruire et recréer les containers du service, même si leur configuration correspond déjà à ce que Swarm connaît. Cette opération peut être utile pour forcer le redémarrage d’un service buggué, par exemple.
(Anti-)affinité
Maintenant que nous savons créer des services, les administrer et les mettre à jour, il est temps de parler des règles d’affinité au sein de votre cluster. Parfois, vous aurez besoin de forcer certains services à ne démarrer que sur certains noeuds physiques. Les raisons peuvent être diverses : conformité réglementaire (par exemple, un seul bout de votre infra est HDS), contraintes techniques (certaines machines appartiennent à un VLAN particulier et d’autres non), etc. Pour gérer ce genre de situations, Docker Swarm dispose de règles d’affinité et d’anti-affinité, basées sur des labels et des contraintes.
Un label est un élément textuel qui peut être ajouté à un node de notre cluster, ou un service. Ils permettent de décrire les services ou l’infra, et peuvent être lus par le cluster. Ces labels peuvent rapidement s’ajouter :
- Sur un node :
docker node update --label-add LABEL=VALEUR <node_name_ou_id> - Sur un service :
docker service update --label-add LABEL=VALEUR <service_name_ou_id>
Et se supprimer :
- Sur un node :
docker node update --label-rm LABEL <node_name_ou_id> - Sur un service :
docker node update --label-rm LABEL <service_name_ou_id>
Ces labels vont nous permettre de définir des contraintes sur les services. Ajoutons un label have_storage=true sur notre première instance (remplacez instance-1 par le nom du node dans docker node ls) : docker node update --label-add have_storage=true instance-1.
Maintenant, nous allons pouvoir créer un service qui n’a le droit de de démarrer que sur les noeuds ayant ce label et cette valeur :
docker service create \
--name nextcloud \
--mode global \
--constraint node.labels.have_storage==true \
--publish published=8080,target=80,mode=ingress \
httpd:latest
Ce service, même s’il est en mode global ne va démarrer que sur le premier noeud, car il est le seul à respecter sa contrainte de placement ! Si un second noeud se met à respecter la contrainte de placement, Docker Swarm générera automatiquement un second container sur le second noeud.
Il est possible de combiner les contraintes, et également d’utiliser des conditions négatives. Par exemple, on pourrait utiliser --constraint node.labels.have_storage!=true pour démarrer notre service sur tout les noeuds n’ayant pas le label have_storage valant true.
Il existe quelques autres contraintes, notamment sur le nom et l’identifiant du node, le système d’exploitation cible (très pratique si vous avez un cluster composé d’hôtes Windows et Linux par exemple !), et ainsi de suite. Le détail est disponible dans la documentation.
Enfin, il est bien entendu possible de mettre à jour les contraintes avec docker service update. 😉
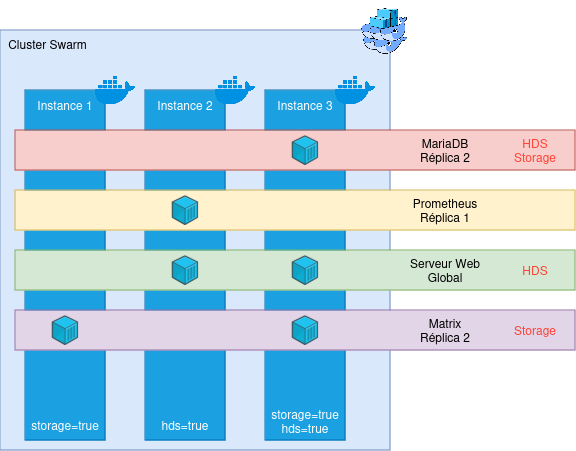
Petite mise à jour du schéma présenté plus haut : Nous prenons désormais en compte des contraintes (indiquées en rouge sur les services). Swarm gère alors les déploiements en prenant en compte ces contraintes de placement de manière automatique et dynamique.
Nous commençons à avoir fait un joli tour d’horizon de Docker Swarm ! Nous avons vu comment les containers communiquent entre eux à travers plusieurs machines ; comment gérer des services et gérer leur placement selon des contraintes techniques ou fonctionnelles. Il ne nous reste plus qu’une chose à voir : comment mettre à jour une machine physique sans tout casser ?
Et mettre à jour une machine entière ?
Dans un cluster, il est logique et normal de devoir effectuer des opérations de maintenance lourdes au fil du temps : mettre à jour un système d’exploitation, ou tout simplement notre Docker Engine. Grâce à Swarm, nous pouvons faire en sorte d’effectuer ces mises à jour sans interruption !
La seule condition pour cela, c’est que vous ayiez au moins 2 noeuds permettant de déployer n’importe quel service (vis à vis des contraintes). Le schéma que nous venons de voir est par exemple un très mauvais exemple : seule une machine dispose à la fois du label storage et hds, ce qui la rend indispensable dans la vie du cluster - sans elle, des services peuvent ne pas fonctionner ! Cela vous posera probléme pour les mises à jour, mais également en cas de panne impromptue de la machine ; puisque Swarm ne saura pas où recréer les containers perdus !
Pour la suite, nous allons considérer que notre cluster dispose de plusieurs noeuds pouvant accueillir chaque service (une fois de plus : faites en sorte que ce soit toujours le cas, pour votre propre santé mentale).
La première étape est d’indiquer à Swarm d’évacuer les containers fonctionnant actuellement sur le noeud que vous souhaitez évacuer. Pour cela, nous allons lancer une commande : docker node update --availability=drain <nom_ou_id_du_node>. Cette commande permet d’indiquer à Swarm que le noeud ciblé n’est plus en état d’accueillir des containers. Swarm va alors arrêter d’instancier de nouveaux containers dessus, et va déplacer tout les containers existant ailleurs (cette opération prend en général moins de deux minutes). Une fois la commande effectuée, vous pouvez vérifier avec le classique docker container ls l’état de votre noeud physique. Une fois que la liste de containers est vide, vous pouvez faire ce que vous souhaitez sur le noeud, votre cluster ne sera pas impacté : coupez Docker, mettez le à jour, redémarrez la machine… Bref, vous êtes libre !
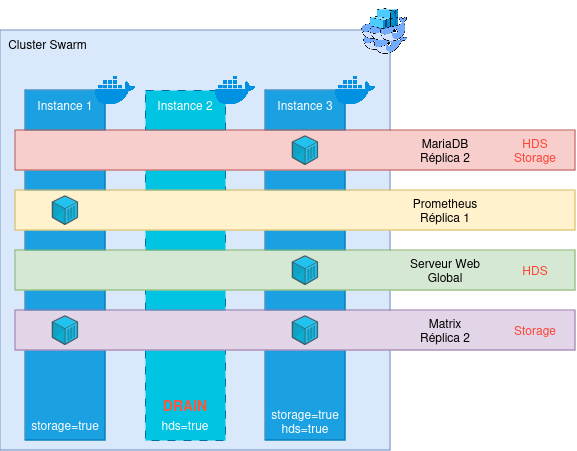
Une fois vos opérations de maintenance terminées, autorisez Swarm à ré-utiliser ce noeud : docker node update availability=active <nom_ou_id_du_node>. Les containers vont commencer à se re-créer dans le cluster.
Il existe également le mode pause, qui permet d’empêcher à Swarm de créer de nouveaux containers, sans tuer les existants.
Un guide plus complet sur une opération de maintenance poussée est disponible sur ce blog, sous forme de Retour d’Expérience : Mettre à jour un cluster Swarm sans interruption.
Voilà, vous savez désormais (presque) tout sur Swarm ! N’hésitez pas à bidouiller davantage (notamment en vautrant un noeud volontairement) pour évaluer la résilience de l’outil par vous même.
Swarm - RETEX en production
Comme je le disais au début de ce billet (c’était il y à longtemps, je sais !), je suis réellement passionné par Swarm : c’est simple, léger, et facile à comprendre. C’est une technologie simple mais qui répond à de très nombreux besoins tout en gardant la philosophie KISS que j’affectionne tant.
Et cette fascination, j’ai pu la développer au cours d’une expérience professionnelle de plus de trois ans, en manageant plusieurs clusters Swarm hébergeant au total plus de 150 services, allant du site web statique à des bases de données, en passant par des micro-services. J’en profite d’ailleurs pour remercier Claude & Micka pour le choix technologique qui était très pertinent (et miser sur Swarm en 2020, fallait oser vu la traversée du désert que le projet venait de vivre !).
Au cours de ces trois ans, on a vécu des hauts et des bas sur l’infrastructure, mais Swarm n’a (presque) jamais été en cause. C’est un outil d’une robustesse incroyable, qui arrive à survivre à des cas extrêmes (je repense notamment à la fois où nous avons perdu nos stockages réseaux pendant 6 heures, ou la fois où deux machines sont mortes en simultanné, imposant Swarm à tourner en mono-node…).
Avec l’outillage qui va bien (notamment OpenTofu pour la partie provisionning et Ansible pour le déploiement), il est possible de faire de très belles choses avec Swarm, pour un coût en run très restreint : s’occuper du cluster en lui-même est un non-sujet, et mettre à jour un Swarm est largement moins contraignant que de mettre à jour un mono-node Docker, puisque nous n’avons aucune interruption de service.
Les mises à jour, parlons-en : Swarm est très stable sur son fonctionnement et ses APIs : Nous avons déjà fait des mises à jour de 6 majeures d’écart (Docker Engine v20->v26) sans aucun soucis de compatibilité. En bref, c’est robuste et ça ne vous laissera pas tomber.
En bref, tout le monde est content du choix de Swarm, et son usage est prévu pour s’ancrer dans les années à venir chez BeYs.
Au final, la seule ombre au tableau, c’est (peut-être) l’écosystème.
Écosystème Swarm
En effet, l’écosystème autour de Docker Swarm est assez peu développé, notamment à cause de l’affreuse période 2014-2018, et de l’hégémonie de Kubernetes.
Sur le produit en lui-même, Mirantis (qui a racheté les activités “Entreprise” de Docker en 2019) contribue de plus en plus, et devrait normalement apporter le support du Container Storage Interface (CSI) courant 2025, ce qui va fortement améliorer la gestion des données entre les noeuds (actuellement, il faut tout se farcir à la main, avec un GlusterFS, un CephFS ou autre). De plus, un certain nombre de contributeurs travaillent sur le code de Swarm dans le dépôt Github de moby. Docker Swarm est donc loin d’être mort (et est même plus vivant que jamais).
Sur l’écosystème autour, de plus en plus de tentatives de structurer et d’outiller Swarm apparaissent. On peut déjà citer la collection Ansible dédiée à Docker (qui inclut 100% de Swarm), un super système de tâches planifiées, et mêmes des tentatives de faire un ArgoCD-like pour Swarm.
De nombreux projets existent (le Github “Awesome Swarm” en est la preuve), n’hésitez pas à aller y faire un tour et contribuer si vous avez un peu de temps !
Pour conclure
Pour conclure, Docker Swarm est un super outil d’orchestration pour vos containers. Il est certes moins complet que Kubernetes, mais ce qu’il perds en fonctionnalité, il le perds également en complexité. Swarm est idéal pour des équipes n’ayant pas besoin du RBAC de Kube, et qui souhaitent garder la main sur leur infrastructure, tout en apportant de la résilience à leur infrastructure.
Et avec l’arrivée prochaine de CSI dans Swarm, il est plus que temps de lui donner une nouvelle chance, et d’oublier les erreurs du passé !