Mettre à jour un cluster Swarm sans interruption
This article is also available in English.
Lorsqu’on héberge des services potentiellement critiques, nous aimons nous dire que l’infrastructure est totalement résiliente, et surtout, que nous pouvons la modifier sans impact pour nos clients. Les finalités sont multiples, mais aujourd’hui, nous allons nous intéresser au nerf (souvent oublié) de la guerre : les mises à jour. Et quand je parle de mise à jour, je ne parle pas de mettre à jour vos services, que nenni : je parle bel et bien des mises à jour que personne ne veut faire, à savoir celles des systèmes d’exploitations et des logiciels sous-jacent à votre infrastructure.
Aujourd’hui donc, retour d’expérience sur la montée de version d’un cluster Docker Swarm, sans interruption de service.
Environnement existant & cible
Notre environnement existant est le suivant : nous avons trois machines virtuelles déployées sur un OpenStack, amorçant AlpineLinux 3.14. Ces trois machines virtuelles forment un cluster Docker Swarm, en version 21. Ces trois machines sont accessibles depuis les Internets sur le port 443. Pour cela, un Traefik est déployé en réplication globale (un par nœud), et expose son port vers l’extérieur.
Les trois instances communiquent entre elles via un réseau virtuel Neutron. Par mesure de sécurité, les réseaux virtuels Docker sont également chiffrés via le chiffrement IPSec natif à Docker Swarm.
A l’extérieur, les machines sont exposées grâce à un DNS commun : les trois instances disposent chacune d’une IPv4, et
*.cluster.my-example.com contient les trois adresses IP : nous avons donc un DNS round-robin. Dans les faits, nous
avons également un load-balancer au-dessus qui s’occupe de faire du failover au besoin, mais ce load-balancer n’est pas
sous notre contrôle, nous considérerons donc qu’il est absent et qu’il agit comme un client normal ici.
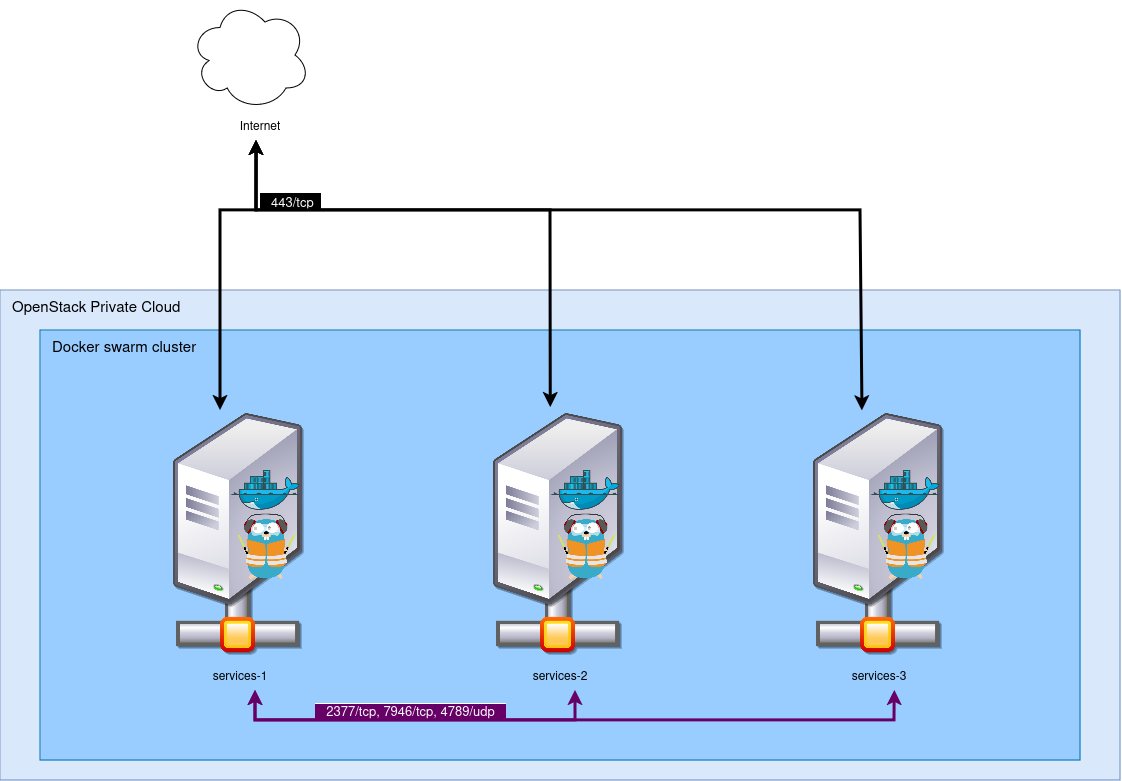
Nous désirons monter de version notre cluster, pour le basculer en Alpine 3.18 (oui, ce billet a tardé à sortir !), et Docker Engine 26. Par ailleurs, nous souhaitons modifier plusieurs configurations situées dans notre fichier d’initialisation, ce qui va impliquer de devoir détruire et reconstruire les instances.
Les instances sont construites via OpenTofu sur un OpenStack privé, et déployées avec Ansible.
Le cluster Docker Swarm expose environ 50 services, en grande majorité derrière Traefik. Les services sont monitorés et supervisés, donc à la moindre coupure, ce sera un ticket JIRA… Et on aime pas les tickets JIRA. 😣
Contraintes
Pour cette migration, nous nous fixons deux contraintes :
- Nous ne devons pas engendrer de coupure auprès des utilisateurs finaux ;
- Nous ne devons pas être coûteux en ressource : dans la mesure du possible, nous allons tenter de ne jamais dépasser les trois instances dans le projet. En réalité, cette contrainte est auto-imposée, pour le challenge, puisque nous sommes sur Cloud privé sans contrainte de capacité ni de coût.
Concept théorique
Dans la théorie, la migration devrait ressembler à ceci :
- On prend le premier nœud ;
- On l’isole du grand public ;
- On vide les services ;
- On détruit/recréé l’instance ;
- On le fait joindre le cluster ;
- On le rouvre au public.
Le tout, trois fois. Pas d’objections ? Non, sûr de sûr ? Bon bah, c’est parti alors.
Nous allons cependant nous ajouter une contrainte de “propreté” : toutes les actions que nous ferons devront être effectuées via OpenTofu, et pas à la main. L’idée derrière est de pouvoir un jour automatiser le processus, et, en attendant, le documenter pour les prochaines personnes qui passeront sur le projet.
1. Isolation
Dans un premier temps donc, nous allons isoler la première instance qui sera victime de la réinstallation. Pour cela, il
nous suffit de supprimer l’enregistrement DNS de *.cluster.my-example.com qui pointe vers cette machine, compte-tenu
de notre configuration.
Sauf que voilà, deux problèmes pointent le bout de leur nez :
TTL (Time To Live)
Afin de soulager les serveurs DNS et d’éviter de générer du trafic inutile, les enregistrements DNS disposent d’un TTL, indiquant au bout de combien de temps un client doit effectuer de nouveau une requête DNS pour obtenir une résolution à jour. Plus le TTL est long, plus la propagation est lente. Notre zone DNS était configuré avec un TTL de 3600 secondes, soit une heure. Nous mettons temporairement à jour le TTL pour qu’il soit de 300 secondes (5 minutes), afin de ne pas avoir à patienter une heure entre chaque modification.
OpenTofu
Notre OpenTofu n’est pas du tout conçu pour retirer les enregistrements DNS à la volée : il récupère la liste des
instances générées, et ajoute chaque IP flottante qu’il trouve dans l’enregistrement. Il est donc temps de modifier un
peu notre OpenTofu : Nous ajoutons une variable instances_in_maintenance qui est un tableau de chaînes de
caractères. Les instances dont le nom est mentionné dans ce tableau seront exclues de l’enregistrement DNS. Ci-dessous
un aperçu du code.
variable "instances_in_maintenance" {
default = []
}
resource "openstack_dns_recordset_v2" "public_record" {
zone_id = "xxxxxxxxxxxxxxxx"
name = "*.cluster.my-example.com."
ttl = 300
type = "A"
records = compact(
toset(
flatten(
[
for k, v in openstack_compute_instance_v2.instance :(contains(var.instances_in_maintenance, v.name) ?
"" :
openstack_networking_floatingip_v2.fip[k].address)
]
)
)
)
}
Note : le code OpenTofu est expurgé de très nombreuses parties inutiles à la compréhension de l’article, et est fourni sans garantie de fonctionnement ici.
Ici, la magie réside dans l’argument records de notre enregistrement DNS : Pour chaque instance créée, nous regardons
son nom. S’il est présent dans la liste instances_in_maintenance, son IP n’est pas rajoutée.
Nous lançons un premier tofu plan pour vérifier que notre change ne casse pas tout, puis un tofu apply avec notre
première machine (swarm-1) dans la liste des hôtes en maintenance. Maintenant, il n’y a plus qu’à attendre 5 minutes
pour que la propagation DNS se fasse partout.
2. Purger les services
Maintenant que le nœud est inaccessible, il est temps de le purger. Pour cela, rien de plus simple, puisque Docker Swarm
permet de modifier la disponibilité d’un noeud, notamment pour des actions de maintenance. Il suffit de taper la
commande docker node update --availability drain <node_name> pour vider le nœud de ses services, et les faire
redémarrer ailleurs. Nous en profitons pour forcer le nœud à quitter le cluster : comme nous effectuons une
réinstallation complète des instances, l’identifiant unique de ce nœud sera perdu. Indiquer son départ à Swarm son
départ permet de réduire la charge réseau, et les risques de ré-élection de leader en boucle. Pour cela, nous lançons la
commande docker node demote <node_name> suivi de la commande docker swarm leave sur notre nœud en cours de mise à
jour.
Les services sont purgés et le nœud a bien quitté le cluster, nous pouvons maintenant le détruire.
3. Détruire et recréer l’instance
Pour détruire et recréer l’instance, nous allons bien entendu utiliser OpenTofu. Cependant, lorsque nous avons créé
notre stack, nous n’avions pas pensé avoir besoin de supprimer une seule machine, nous avions donc utilisé un count.
Pour les gens qui ne sont pas familiers à OpenTofu, cette instruction permet de demander à l’outil d’effectuer une
action plusieurs fois ; et on peut récupérer l’itération en cours avec l’argument count.index. Cette option est très
simple et pratique, mais elle présente un énorme défaut : on ne pilote pas les instances supprimées par OpenTofu. Si
nous changeons notre count=3 par count=2, OpenTofu détruira systématiquement la dernière instance qu’il a créé.
C’est problématique pour nous, puisque nous souhaitons justement faire l’inverse !
Nous n’avons alors pas de choix que de modifier notre OpenTofu pour passer sur un système de for_each. L’argument
for_each permet de passer un tableau à OpenTofu, qui va effectuer une action pour chaque élément du tableau, et s’en
servir comme clé. Par exemple, si nous utilisons le tableau ["0","1","2"] sur un module de création d’instance,
OpenTofu va créer un dictionnaire, qui contiendra pour chaque clé une instance associée précise. Ce système nous permet
ainsi de pouvoir supprimer une instance précise (par exemple 1), sans altérer les deux autres.
Code avant :
resource "openstack_compute_instance_v2" "instance" {
name = "swarm-${count.index}"
image_id = "xxxxxxxxxxx"
flavor_name = "medium-4g"
network {
uuid = "xxxxxxxxxxxx"
}
count = 3
}
Note : le code OpenTofu est expurgé de très nombreuses parties inutiles à la compréhension de l’article, et est fourni sans garantie de fonctionnement ici.
Code après :
variable "instances" {
default = ["1", "2", "3"]
}
resource "openstack_compute_instance_v2" "instance" {
name = "swarm-${each.value}"
image_id = "xxxxxxxxxxx"
flavor_name = "medium-4g"
network {
uuid = "xxxxxxxxxxxx"
}
for_each = var.instances
}
resource "openstack_dns_recordset_v2" "public_record" {
zone_id = "xxxxxxxxxxxxxxxx"
name = "*.cluster.my-example.com."
ttl = 300
type = "A"
records = compact(
toset(
flatten(
[
for k, v in module.swarm_instance : (contains(var.instances_in_maintenance, k) ? "" : v.fip[0].address)
]
)
)
)
}
Note : le code OpenTofu est expurgé de très nombreuses parties inutiles à la compréhension de l’article, et est fourni sans garantie de fonctionnement ici.
Nous tentons à nouveau de lancer un tofu plan, et la, c’est la catastrophe : OpenTofu souhaite tout détruire et tou
recréer ! Et oui, notre changement de count à for_each est très loin d’être anodin, et OpenTofu ne sait pas gérer un
tel changement. Une seule solution alors, pour ne pas tout casser : modifier le fichier .tfstate à la main.
Je ne détaillerai pas le processus ici, car il était très manuel, très long et très peu intéressant. Dans le concept, voici ce que nous avons fait :
- Nous avons déployé (et immédiatement détruit) un nouvel environnement avec le
for_each, afin de récupérer la structure du fichier.tfstate; - Puis nous avons calqué l’ancien
.tfstatesur le format du nouveau ; - Et nous avons utilisé ce
.tfstatemodifié par la suite.
Si vous avez besoin de faire cette opération vous aussi, assurez-vous d’avoir une backup de votre fichier .tfstate
bien au chaud !
Une fois ces désagréments (et les nombreuses adaptations requises) passés, nous avons pu détruire et recréer notre
instance. Pour cela, ne surtout pas lancer un tofu destroy, mais bel et bien deux fois tofu apply : une fois après
avoir retiré l’instance de la variable instances, et une fois après l’avoir remis.
Notre nœud est réinstallé en Alpine 3.18 🎉.
4. Rejoindre notre Cluster Swarm
Dans notre contexte, nous avions déjà une vaste collection d’outils construits avec Ansible qui nous ont permis de
réinstaller Docker et de faire rejoindre le cluster au nœud de manière automatique. Si cela n’est pas votre cas, il vous
suffit de réinstaller Docker (sous Alpine, apk add docker-ce), et de le faire rejoindre (sur un nœud encore dans le
cluster, tapez la commande docker swarm join-token manager pour obtenir un token).
Votre nouveau nœud commence dès lors à accueillir de nouveau des services. Une fois notre Traefik revenu sur ce nœud, nous pouvons rouvrir le nœud au public !
5. Rouvrir le nœud au public
Maintenant que notre nouvelle instance fonctionne et que les services sont revenus dessus, nous pouvons rouvrir cette
instance au grand public. Pour cela, rien de plus simple : il suffit de retirer l’instance de la variable
instances_in_maintenance, et de relancer un petit tofu applý. Attendez ensuite que la propagation DNS s’effectue, et
vous avez terminé (pour ce nœud).
Il nous vous reste plus qu’à refaire ça deux fois ! Rassurez-vous, comme nous avons déjà essuyé les plâtres avec la première instance pour OpenTofu, vous ne devriez plus avoir de mauvaises surprises…
Qu’en retenir ?
Nous avons tiré de très nombreux enseignements de cette opération de maintenance, qui n’a pas été de tout repos.
Swarm
Premièrement, nous pouvons en retirer que Docker Swarm est, une fois de plus, stable et fiable. Malgré les très nombreuses opérations concernant ses nodes, et toutes les sous-opérations que cela a pu engendrer (re-balance des services, redémarrage de services, routes réseaux à recréer, etc), Swarm ne nous à jamais fait faux bond ! Un véritable atout dans ces conditions. Par ailleurs, la grande différence de versions (5 versions majeures d’écart) ne l’a pas perturbé pour autant.
En bref, Docker Swarm, ce n’est pas hype, ni très “sexy”, mais ça fonctionne (et ça, c’est le plus important !).
Notre architecture “réseau”
Le DNS round-robin n’est pas idéal pour de nombreuses raisons, et nous le savons. Cette méthode de fonctionnement nous a une fois de plus ralentis, à cause des délais de propagation. A l’avenir, nous devrions songer à utiliser un réel load-balancer afin de nous éviter ce genre de soucis. Pour rester sur de l’OpenStack, Octavia semble être une solution toute trouvée à ce problème, mais d’autres outils pourraient trouver la même finalité.
En dehors de ce léger désagrément, rien à signaler non plus de ce côté là, nous sommes assez content de notre infrastructure en place.
Traefik, lui, a permis de rendre réellement invisible les migrations au fur et à mesure qu’elles étaient effectuées. Enfin, Traefik, et le service mesh + dynamic DNS de Docker Swarm qui nous a, lui aussi, bien aidé. 😉
Note pile d’automatisation
En réalité, notre véritable problème aura été notre pile d’automatisation. Non pas la faute des outils, mais bel et bien
de nous, qui n’avions pas suffisamment anticipé nos besoins : maintenant que nous regardons dans le rétroviseur, il
semble évident que le besoin de pouvoir supprimer des instances de manière indépendante aurait dû être un indispensable,
et ce, dès le début de la rédaction de notre stack OpenTofu. Toutefois, nous pouvons noter la capacité d’adaptation d'
OpenTofu : malgré nos erreurs de jeunesses, nous avons réussi à corriger le tir en un peu moins d’une demi-journée
(modification du .tfstate inclus), et à atterrir à notre état final sans aucune casse. Et ça, c’est classe à Dallas ! 😎
Notre stack Ansible, elle, a été largement à la hauteur, et nous a permis d’effectuer toutes les actions dont nous avions besoin sans aucune difficulté.
Pour conclure
Nous pouvons conclure cet article en disant que l’ensemble des objectifs ont été atteints : nous avons réussi à mettre à jour un cluster entier sans interruption pour nos utilisateurs, sans avoir à dériver de notre socle technologique. Nos services (majoritairement codés en Go) ont parfaitement encaissé le coup, et notre infrastructure “bas-niveau” ( Alpine/Docker Swarm) et notre pile d’automatisation (Ansible/OpenTofu) nous ont donné une complète satisfaction, et nous ont conforté dans la certitude que nos choix techniques sont cohérents avec nos besoins.
En bref, c’est une belle expérience, et une belle réussite !