Using a RAG to extract and consolidate data from a document corpus; is it possible?
⚠️ This article is an automated translation. While I personally reviewed the content before publication, some inaccuracies may remain. Read the original French version.
If managing IT heritage and associated data has been a fundamental subject for companies with an IT park for decades, there is however a close but unfortunately under-exploited field: that of a company’s documentary heritage. Yet, this field is probably the most transverse and the most generic to the very notion of a company: every company has its own internal processes, its calls for tenders, its employees’ Curriculum Vitae, its invoices (both supplier and customer), the calls for tenders it responds to, etc. Through this article, we will try to answer the following questions:
- Can we, on the one hand, extract a set of information from a document and store it in a structured way?
- And, on the other hand, can we query this information through natural language, for example by means of a Chatbot?
To answer these two questions, we have conducted several experiments aimed at comparing solutions currently available “off-the-shelf”, but also some implementations proposed in the research world. Of course, these solutions mostly rely on text understanding algorithms from artificial intelligence, in order to detect, identify and catalog the content of documents automatically and agnostically; since the format of documents can vary significantly over time.
For all these tests, we based ourselves on a documentary corpus composed of several CVs of invented people, as well as several calls for tenders received by the company dating back more than two years. Each CV is composed of a last name, a first name, and a set of different professional experiences and technical skills. Our objective: to succeed in forming the dream team for this project to respond to our client’s project. This experimentation is part of a more general approach at Zenika, aiming to better know our clients’ technical context in order to facilitate the identification of their needs, as well as the people most likely to respond to them.
Given that, in a real usage context, we will transmit potentially confidential or critical data to this tool, we wish to use only solutions deployable on-premises, in order to avoid any data leakage to third-party operators.
Discovery of a RAG
A RAG (Retrieval-Augmented Generation) is a technique that allows an Artificial Intelligence to retrieve the content of a document in order to extract and summarize information from it. In detail, the RAG will read the document and extract its content, before breaking it down into chunks. This step is crucial, because LLMs can only take a certain amount of information in context.
In an induced way, the RAG will therefore manage another important step: when a query arrives at the LLM, the RAG will take care of detecting the pieces of documents potentially interesting to give them in context to the LLM.
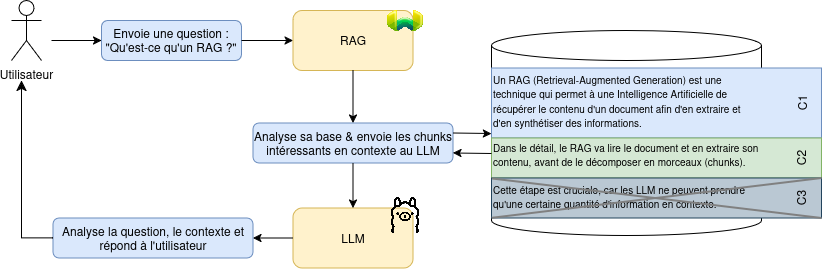
Figure 1 - General operation of a RAG
There are several ways to split a document into chunks. The most basic approach consists of splitting based on the number of words, or sentences. For example, we will be able to configure that each chunk will be composed of 10 sentences, or 150 words. The RAG will then index the content of this chunk, and send it back in full to the LLM when it considers that the chunk has relevance in the context requested by the user.
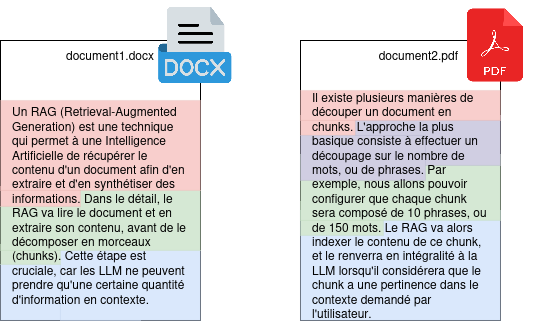
Figure 2: Splitting a document using a sentence separation.
In the example above, we have two documents, which have been split into 7 chunks (one chunk per sentence). When the user sends a query to our LLM, the RAG will take care of detecting potentially interesting chunks, and inject them into the LLM as context in order to tint the response with the details contained in our documents.
It should be noted that configuring the size of a chunk is not trivial: larger chunks will allow for better preservation of the document’s global context, but in return, the RAG will have to select fewer chunks to send. This setting is therefore strongly dependent on your type of documentary corpus.
First Trials
The first step was to list community solutions already available for our use. Several tools seemed promising to us, which we decided to experiment with in more detail:
These tools all have in common that they allow simply building a RAG, usable through a simple and intuitive graphic interface. Most of our tests focused on Verba, as the latter allows much more extensive configuration of the chunking method, the models used, etc.
We also experimented with Dify, which is a slightly different tool, as it is more about designing complex workflows, allowing successive actions to be performed (API calls, sending context to an LLM, etc.). Given that it is much more difficult to set up and that our business need has no real use for it, we set this solution aside although it is very promising.
To function, these tools need two data models (LLM, for “Large Language Model”). These LLMs will be the heart of the system, since they are the ones that will perform the tasks of document extraction, analysis of user requests and data reconciliation. Some models are available for free use (notably Llama), and others are proprietary (like GPT-4, designed by OpenAI). We experimented with the last three models of Llama (3.1-8b, 3.2 and 3.3) in order to define the model with the best “response quality / execution speed” ratio. For text extraction, we used nomic-embed-text, which is a model specialized in extracting information from documents.
In order to define the best model, we launched several tests with Verba on each of the models at our disposal:
- A first test consists of asking a model to summarize a document for us, for example one of the CVs from our test set. On this exercise, we find that our three models (llama3.1-8b, llama3.2 and llama3.3) return quite similar results. With identical execution hardware, the llama3.1-8b and llama3.2 models respond in almost identical times, whereas llama3.3 takes several tens of seconds to generate a complete response;
- A second test consists of sending a presentation of about 60 slides presenting an action plan, and asking the LLM to summarize the provided document. There, results diverge between llama3.1-8b and our two other models: indeed, version 3.1-8b has a lot of trouble processing the entire provided context. Thus, the LLM contents itself with returning a list of generic elements, decorrelated from the real content of the presentation. In contrast, models 3.2 and 3.3 return more complete and relevant information.
We therefore determined that the most efficient model for our use case would be llama3.2.
This test also allows us to confirm that the RAG concept is valid and applicable when analyzing a single document: in each of our tests, we were able to verify that the LLM returns consistent results in phase with the content of the sent document. This means that the LLM accepts and correctly uses the specific context to extend its original knowledge base.
However, our tests took an unexpected turn when we began to ask the LLM to consolidate data from several documents simultaneously.
Chunking, or the Hell of Consistency
As seen previously, when the RAG ingests a document, it will break it down into several pieces, called chunks. Quite logically, each chunk will contain a piece of the knowledge brought by the document. This splitting is essential for an LLM’s work: since the LLM only accepts a certain number of characters in context, it is impossible to communicate our entire documentary base to the LLM.
During a query, the RAG will intercept the request before it is transmitted to the LLM, and check in its documentary base for chunks that have an interest within the framework of the question asked by the user. Then, the RAG will transmit the question as well as the chunks judged “interesting” to the LLM for processing. This operation however implies an important limitation: The LLM is incapable of knowing the complete context of the document, since it only receives a part of it.
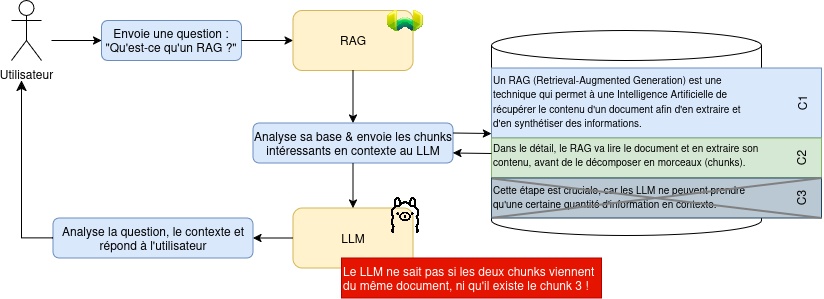
Figure 3: Resumption of our global diagram, with clarification on chunks.
The absence of complete knowledge of the context causes various limitations in the operation of a RAG, notably the fact that no data consistency can be guaranteed. This limit was unfortunately very quickly encountered during our tests; and we were able to confirm that the chunk system is indeed at the origin of the problem, by voluntarily reducing the size of the sent documents. In more detail, here is the experimental protocol we used to confirm this problem:
At first, we sent 5 complete CVs to the LLM; each CV being composed of 3 to 5 pages. We asked it the following question: “Based on all the documents at your disposal, give me the names of a team capable of developing a project in Golang, using Terraform and GitLab, and a PostgreSQL database”. Each time, the LLM indicated it was unable to provide an answer to this question, because no person is in its documentary base. This absence of response is due to document splitting, because the RAG identifies pieces of documents containing only technology names, but not the first and last names of people. The LLM then does not understand the request provided to it, because it is not capable of reconstructing the complete context of the documents transmitted to it by the RAG.
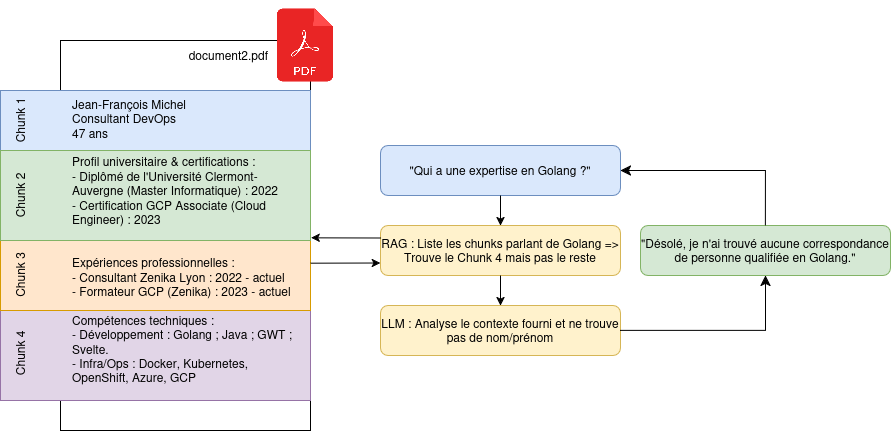
Figure 4: Demonstration of the chunking problem with a CV example.
Then, we deleted the 5 documents, and sent back the summary of each CV, each time composed of the last name, first name, position and a short biography of each person. In the summary, we took care to slip in the technologies wanted for the project. When we submitted the same prompt to the LLM, it was able to answer us with a consistent three-person team-type, composed of people present in the CVs. This solution is possible because the document is small enough to fit in a single chunk, and the RAG will therefore communicate the entire document to the LLM, which will thus have a complete knowledge of the context. This solution works, but has obvious limitations, as the context that can be sent to the LLM is limited in size. This solution is therefore not viable in the long term, or with long documents.
By completely disabling chunking, the result is not more convincing: the context then exceeds the limits tolerated by the LLM, and the latter then simply ignores the documents provided in context, which results in an invalid response.
During our tests, we experimented with another confusing situation: By taking a prompt and a set of functional documents, and by asking the same prompt several times, our model (llama3.2 here) began to strongly drift in its responses. If the first iteration returns a totally consistent and valid result, the second, third and fourth iterations return increasingly aberrant results (confusions in people’s capacities with respect to their CVs, invention of new first/last names, etc.). The conservation of context seems therefore to be a limitation to the consistency of the data set, even without a prompt dedicated to lowering the response quality.
We are therefore facing a double limitation here:
- We cannot disable chunking without destroying the interest of the RAG;
- We cannot keep chunking because the LLM generates improbable responses (also called hallucinations).
Semantic & Axiom Chunking
By browsing various research documents, we came across two potential solutions to our contextualization problem.
Semantic Chunking
The objective of semantic chunking is quite simple: Instead of splitting documents based on an arbitrary number of words or sentences, we are going to use a natural language engine to understand the document’s content, and split it by semantic grouping. This operation will result in a set of chunks of different sizes, but each containing a set of information strongly linked together.
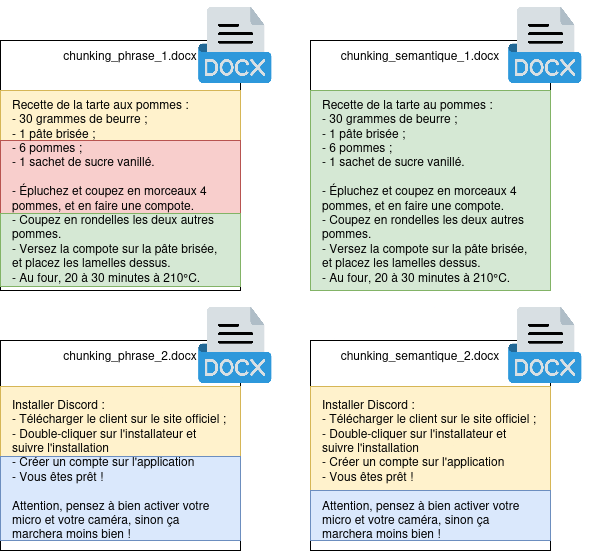
Figure 5: Sentence vs. semantic splitting. The document is split consistently in order to preserve a context specific to each chunk.
In this way, we reduce the risk of hallucination by giving our model consistent information already qualified by a tool beforehand. However, this approach has various limitations. First, this method is still highly experimental, and implementations are rare, which forces one to develop this kind of functionality oneself. For this, some libraries, such as spaCy, can be very useful. Second, this operation requires more energy and calculation time, as the document must undergo an analysis step before being split and stored; and this cost is not negligible on large documentary corpora. Finally, this method relies on linguistic analysis: documents with convoluted phrasing or in languages not supported by our linguistic analyzer could return a lot of bad results and pollute the rest of the documentary corpus.
Axiom-based Operation
Another operation proposed in research is to store axioms instead of the entire document. The objective here is to break down information into a set of minimal and self-sufficient sentences.
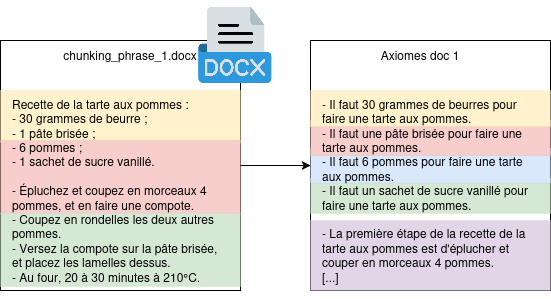
Figure 6: Sentence vs. axiom splitting. Each axiom becomes a chunk that can be communicated in context to the LLM.
For an axiom to be considered valid, it must be atomic (a single truth is expressed in the axiom), self-sufficient (its context is totally defined within it), and must not be separable into several sub-axioms. This approach significantly improves the LLM’s response quality on large data models (researchers note a relative improvement of 25%, i.e., an absolute improvement of 11% in result accuracy), but increases document ingestion time. Furthermore, there is the problem of generating these axioms: This approach requires calling an LLM to take document information and extract information from it. In the same way as for semantic chunking, problems related to natural language can occur, and are even more numerous: in an axiom-based operation, we seek to eliminate all nominal pronouns.
For example, in the document “Florian is a developer, who also likes apples. He is also interested in aeronautics”; we expect to have three axioms:
- “Florian is a developer”;
- “Florian also likes apples”;
- “Florian is interested in aeronautics”.
These axioms are valid and easily understandable for a human being; but are not sufficient for an LLM: since each axiom can be sent individually to the LLM, the pronoun “He” becomes undefined; it is then impossible to know who is really concerned by this axiom.
This operation, trivial for a human being, is however very complex for an LLM, as it requires fine knowledge of the language and its specificities. In our attempts, even with proprietary models (like GPT-4), we had quite intriguing results (such as, for example, “Apples love aeronautics”). This approach therefore requires preliminary human processing to verify the validity of the axioms, and effectively limits its use at scale.
Conclusion
The RAG approach presents an interesting solution in tasks requiring summarizing a document and exploiting its content in a natural language conversation with an LLM. However, the operation of an LLM’s contextualization imposes strong constraints that are difficult to overcome, because the workarounds impose a complete semantic analysis of the document, which can be a source of error and approximation strongly harming the quality of the contexts provided to the LLMs.
While our tests were able to highlight a real use case within the framework of a single document, our various attempts to obtain a summary or consolidation of several documents never resulted in a suitable result for intensive or systematized use: sources of error remain too frequent and content quality suffers as a result.
Other alternative solutions seem to be emerging, notably the concept of a knowledge graph. This approach, notably explored by GraphRAG, consists of creating weighted graphs containing document data in order to be able to query this graph and thus obtain understandable and reproducible results; thus reducing the risk of LLM hallucinations. However, this approach still requires strong semantic analysis of the text provided in context; and therefore causes the same problems as those mentioned earlier about semantic chunking. In this approach, we move strongly towards already existing and proven solutions (RDF, Semantic Web), using the power of AI to identify and classify information from a document.
Sources
- Dense X Retrieval: What Retrieval Granularity Should We Use? [arXiv:2312.06648]
- From Single to Multi: How LLMs Hallucinate in Multi-Document Summarization [arXiv:2410.13961v1]
- MDCure: A Scalable Pipeline for Multi-Document Instruction-Following [arXiv:2410.23463]
- Generating Knowledge Graphs from Large Language Models: A Comparative Study of GPT-4, LLaMA 2, and BERT [arXiv:2412.07412]
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization [arXiv:2404.16130]
This article is a repost of the blog post written for Zenika.