That’s it, here we are at the end of the year 2025! A year that has been very rich in technical and human experiences for me; notably following my
change of job: new colleagues, new work techniques, new challenges. But above all, 2025 was for me the opportunity to realize many projects and
desires that had been hanging around in my head for several years already. We are of course going to talk about conferences, but also about teaching,
my job, Clermont’ech, and above all, the beautiful projects in mind for 2026.
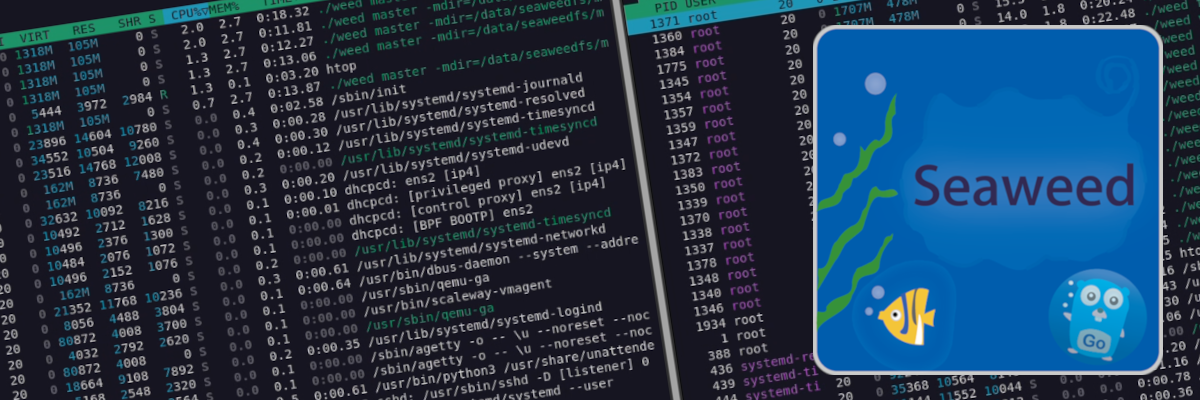
During this year, I was faced with a client with the thorny issue of object storage in business: Within this company, it is impossible to consider a “cloud” solution for their storage: indeed, they have many regulatory and legal constraints that formally prevent them from delegating data storage to an external service provider. The question therefore arises: how to provide them with effective, scalable, on-premise object storage, and preferably without paying absurd license fees.
Train enthusiasts and Volcamp (and elsewhere) curious people, welcome to this making-of the table presented during my conference on October 2nd!
Unfortunately, it was impossible for me to talk to you longer about the table itself during the conference, so this blog post is here for that: to let you discover all the stages of design of the table and the decorations. Be careful, there are many images!
Day 1 - Kick-off!
During the first day of construction, we set out to find an element allowing us to lay our rails. For this, we had to find a flat, rigid and light surface. Our choice fell on a plywood board that was lying around.
In the previous post, I explained how my personal infra works, with an Ansible structure allowing me to deploy each service independently of the others. This way of managing my infra has allowed me to save a lot of time, but there was still one long, boring, and repetitive thing to do: Updating my infra.
If you have ever hosted services yourself over a fairly long time, you know that updates are the poor relation of infrastructures (and even in companies, don’t tell me your park is always up to date). If modern containerization and orchestration solutions (Podman, Docker, Kubernetes Swarm, Rancher, […]) have solved many problems by cleanly decoupling the OS and services, it remains that updates are often experienced as a suffering: it’s pure run time, lost “doing nothing”. And generally, updates happen like this:
At the beginning of the year, I decided to clean up my home infra (which I use to store/share documents, manage my passwords, host this blog, etc.). Over the years, this infra had become increasingly complex (due to more and more services), and above all, I basically never had time to make my changes properly: I was in a total YOLO approach, with a GitLab 15 exposed to the four winds, abysmal performance on half of my infra (👋 my Nextcloud which survived for a year with 500MB of RAM and half a CPU), a frightening proliferation of servers, a questionable backup strategy… In short, it was a mess.
When I rebuilt my “home” infrastructure in late 2024 (as my 2015 dedicated servers were starting to slightly reach their end of life), I decided to take the time to think about a real backup strategy. Indeed, backups have long been one of the (many) poor relations of my infra: every night I performed a full backup of my data to one of the FTP servers included in Scaleway’s “Dedibox” offer. To quickly summarize my old backup system, we can note that, on the positive side, it worked (and that’s already not bad). On the negative side… in no particular order, it was slow, it was atrocious in terms of space optimization (140GB every night, yay!), I couldn’t recover a specific file or folder. To summarize, it was a fun way to operate, but it smelled strongly of the 2000s. We’ll skip the basic notions of security; the FTP connection wasn’t even encrypted. 🥴
If managing IT heritage and associated data has been a fundamental subject for companies with an IT park for decades, there is however a close but unfortunately under-exploited field: that of a company’s documentary heritage. Yet, this field is probably the most transverse and the most generic to the very notion of a company: every company has its own internal processes, its calls for tenders, its employees’ Curriculum Vitae, its invoices (both supplier and customer), the calls for tenders it responds to, etc. Through this article, we will try to answer the following questions:
With version 23, Docker (actually moby/swarmkit) added CSI support in Swarm mode. This feature was long-awaited within the (small) Swarm community, as it had been its biggest drawback compared to Kubernetes until then (if we only talk about Swarm’s native features, not the surrounding ecosystem).
What is CSI?
CSI stands for Container Storage Interface. The concept is to standardize how container orchestrators (Docker Swarm, Kubernetes, Cloud Foundry, etc.) handle access to persistent storage (on disk, for example). Indeed, when you use an orchestrator, it means your containers can start on several different machines. However, a major problem arises: how to handle containers that need to store persistent data, since these containers must be able to start on any of the machines in your cluster?
If you’ve ever worked in a company that manages its own infrastructure, you’ve inevitably heard this little phrase: “anyway, it’s always the network’s fault”. And it’s true that the network is often quite cryptic (at least for ordinary mortals like me). Add printers and those !#[@) Nvidia graphics card drivers, and you have the IT Bermuda Triangle: it works, so above all, don’t touch it.
Except that, sometimes, you have to touch it. And this time, our adventure ended in the confines of the Linux kernel. Yet, everything started well: I had my morning coffee, Spotify was playing Black Room Orchestra in my ears, and I was happily coding a frontend in Svelte. When suddenly, a manager walks in with a riddle: “Would you, ladies and gentlemen, happen to know why a network card would not be detected on a clean Debian installation?”. Knowing the joys of Debian’s non-free drivers, Louis, Ju (my colleagues and co-victims in this case) and I put forward some hypotheses for a quick fix. But no, bad luck, the people installing the machines have already tried everything. The cards are apparently fairly esoteric models, are expensive, and above all, the company has bought 16 of them; so we’d better get them working.
In life, we all have battles that we know are lost in advance but that are close to our hearts. A sort of obsession, an irrational thing that no one really understands, except you. Today, let me introduce you in more detail to one of my obsessions: Docker Swarm.
In two words before starting, Docker Swarm is a container orchestrator that has the particularity of doing clustering: you install Docker Swarm on several servers (or virtual machines), and Docker Swarm will automatically distribute your containers across these machines. Docker Swarm has been around for several years now and is considered a mature product that can be used without major drawbacks in production. It is an alternative to another much better known, hyped, and used tool: Kubernetes.
When hosting potentially critical services, we like to think that the infrastructure is totally resilient, and above all, that we can modify it without impact for our customers. The goals are multiple, but today, we are going to focus on the (often forgotten) sinews of war: updates. And when I talk about updates, I’m not talking about updating your services, no way: I’m talking about the updates that no one wants to do, namely those of the operating systems and the software underlying your infrastructure.
This year, I took over a new Cloud Technologies course for third-year engineers at INP Clermont-Auvergne. Wanting to provide them with fun practical exercises (TPs) where we could really push the concept of Cloud Computing to the maximum, I embarked on the somewhat crazy project of deploying an OpenStack with DevStack, all in native IPv6. A look back at 4 weeks of hair-pulling, 4 weeks of sleepless nights, but for a result that is well worth the detour 😊.